个人感悟
本周主要通过一些案例,对之前所学的知识进行复习和深化。首先容器化的应用程序性能分析,依旧可以使用之前的方法来分析和定位,不过要结合命名空间、cgroups、iptables等来综合分析。比如:
- cgroups影响容器应用的运行
- iptables中的NAT会影响容器的网络性能
- 叠加文件系统,会影响应用的I/O性能
对于网络丢包问题分析,要从Linux网络收发的流程入手,结合TCP/IP协议栈的原理来逐层分析。当碰到内核线程的资源使用异常时,很多常用的进程级性能工具并不能直接用到内核线程上。此时可以使用内核自带的perf来观察它们的行为,并找出热点函数,进一步定位性能瓶颈。不过perf汇总报告并不直观,可以通过火焰图来协助排查。
perf对系统内核线程进行分析时,内核线程依然还在正常运行,这种方法也被称为动态追踪技术。动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮助分析、定位想要排查的问题。在Linux系统中,常用的动态追踪方法包括ftrace、perf、eBPF/BCC以及SystemTap等。
- 使用perf配合火焰图寻找热点函数,是一个比较通用的性能定位方法,在很多场景中都可以使用
- 如果仍然满足不了需求的话,在新版的内核中eBPF和BCC是最灵活的动态追踪方法
- 而在旧版本内核,特别是在RHEL系统中,由于eBPF支持受限,SystemTap和ftrace往往是更好的选择
接下来是本周读书笔记
Lesson 46 案例篇:为什么应用容器化后,启动慢了很多?
本课主要学习如何分析应用程序容器化后的性能问题。
实验
sudo docker run --name tomcat --cpus 0.1 -m 512M -p 8080:8080 -itd feisky/tomcat:8
curl localhost:8080
容器内核心应用逻辑比较简单,申请一个256M的内存然后输出“HelloWorld”。等待容器启动后运行curl命令给出了结果“HelloWorld”,但是随后出现Empty reply from server一直connection refused。
查看tomcat log并没有发现问题并且容器状态为Exited,此时利用docker inspect查看容器信息,发现State信息中OOMKilled为true,说明容器是被OOM杀死。但是我们已经指定了-m为512M正常不会遇到OOM问题。
此时利用dmesg命令查看系统日志,定位OOM相关日志,可以看到输出显示:
- mem_cgroup_out_of_memory,超出了cgroup内存限制
- java进程在容器内运行,容器内存的使用和限制都是512M,当前使用量已经超过该限制
- 被杀死的进程,虚拟内存为4.3G,匿名内存页为505M,页内存为19M。
分析可知,Tomcat容器的内存主要用在了匿名内存,其实就是主动申请分配的堆内存。Tomcat是基于JAVA开发,自然想到JVM堆内存配置问题。
重新启动容器,执行下列命令查看JVM堆配置
sudo docker exec tomcat java -XX:+PrintFlagsFinal -version | grep HeapSize
sudo docker exec tomcat free -m #容器内部看到的仍然是主机内存
看到初始堆内存大小InitialHeapSize为126MB,最大堆内存大小为1.95GB,比容器限制要大。因为容器看不到该配置,虽然在启动容器时设置了内存限制,但是并不影响JVM使用。
解决方法:在运行容器时加上 -e JAVA_OPT=“-Xmx512m -Xms512m”限制JVM的初始内存和最大内存即可
重新启动容器后,查看tomcat log发现能正常启动,但是启动时间需要22s。
再次重启容器并使用top来观察输出,发现机器中CPU使用率并不高且内存也非常充足,再看进程上Java进程的CPU使用率为10%,内存使用率0.9%。 其他进程使用率几乎可以忽略。
继续重启容器,top拿到JAVA进程PID之后,再用pidstat分析该进程,发现虽然CPU使用率很低,只有10%,但是wait%却非常高达到了87%,说明线程大部分时间都在等待调度,没有真正运行。
再看我们运行容器时限制了–cpus 0.1,限制了CPU使用。将该值增加大1再重启此时只需要2s即可完成。
小结
在容器平台中最常见的一个问题就是刚开始图省事不进行资源限制,当容器数量增长之后就会经常出现各种异常问题,最终查下来可能就是某个应用资源使用过高,导致整台机器短时间无法响应。因此使用Docker运行Java应用时一定要确保设置容器资源限制的同时,配置好JVM选项。 也可以升级JAVA版本到JAVA10,即可自动解决类似问题。
Lesson 47/48 案例篇:服务器总是时不时丢包怎么办?
丢包率是网络性能中最核心的指标之一
实验
本次实验案例是一个Nginx应用,hping3和curl是Nginx的客户端。
sudo docker run --name nginx --hostname nginx --privileged -p 80:80 -itd feisky/nginx:drop
hping3 -c 10 -S -p 80 XXX.XXX.XXX.XXX
因为Nginx使用的是TCP协议,而ping是基于ICMP协议的,因此我们用hping3来测试。此时输出显示10个请求包值收到5个回复,每个请求的RTT波动较大,小的只有3ms大的则有3s左右。可以猜测3s左右的RTT是丢包重传导致。
从图中可以看出可能发生丢包的位置,实际上贯穿了整个网络协议栈:
- 在两台VM连接之间,可能会发生传输失败的错误。如网络阻塞、线路错误等
- 网卡收包后,环形缓冲区因溢出而丢包
- 链路层,会因为网络帧校验失败、QoS等丢包
- IP层,会因为路由失败、组包大小超过MTU等而丢包
- 传输层,因为端口未监听、资源占用超过内核限制丢包
- 套接字层,因为套接字缓冲区溢出而丢包
- 应用层,应用程序异常而丢包
- 此外如果配置了iptables规则,可能因为过滤规则而丢包
因为VM2只是一个hping3命令,为了简化排查同时假设VM1的网络和内核配置也没问题。因此可能发生问题的地方就是容器内部了。进入容器内部逐层排查丢包原因。
链路层分析
首先查看链路层,通过ethtool/netstat查看网卡的丢包记录,从输出中没有发现任何错误,说明容器的虚拟网卡没有丢包。(注意:如果tc等工具配置了QoS,tc规则导致额丢包不会包含在网卡的统计信息中)接下来检查eth0是否配置了tc规则,并查看有无丢包。
sudo docker exec -ti nginx /bin/bash
netstat -f
tc -s qdisc show dev eth0
qdisc netem 800d: root refcnt 2 limit 1000 loss 30%
Sent 432 bytes 8 pkt (dropped 4, overlimits 0 requeues 0)
此时tc规则中看到,eth0上面配置了一个网络模拟排队规则qdisc netem,并且配置了丢包率为30%。后面统计信息显示发送了8个包,但是丢了4个。
发现这点问题之后,直接删掉netem模块即可。
tc qdisc del dev eth0 root netem loss 30%
此时再次执行hping3命令,发现还是50%的丢包,RTT的波动也很大,从3ms到1s。
网络层和传输层
在容器内部继续执行netstat -s命令,可以看到各协议的收发汇总,以及错误信息。 输出表明只有TCP协议发生了丢包和重传。TCP协议有多次超时和失败重试,并且主要错误是半连接充值。即主要失败都是三次握手失败。
- 11 failed connection attempts
- 4 sgements retransmitted
- 11 resets received for embryonic SYN_RECV sockets
- 4 TCPSynRetrans
- 7 TCPTimeouts
iptables
因为iptables和内核的连接跟踪机制也可能会导致丢包,因此也需要进行排查。要确定是不是说连接跟踪导致的问题,只需要对比当前的连接跟踪数和最大连接跟踪数即可。由于连接跟踪在内核中是全局的,因此需要在主机中查看。
sysctl net.netfilter.nf_conntrack_max
此时当前连接跟踪数远小于最大连接跟踪数,因此丢包不可能是连接跟踪导致。
接下来回到容器内部查看iptables的过滤规则,发现有两条DROP规则的统计数值不是0,分别是在INPUT和OUTPUT链中。这两条规则是一样的,指的是使用statistic模块进行随机30%的丢包。删除这两条规则即可。
iptables -t filter -nvL
Chain INPUT
pkts bytes target prot opt in out source destination
6 240 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.299999999981
Chain FORWARD
pkts bytes target prot opt in out source destination
Chain OUTPUT
pkts bytes target prot opt in out source destination
6 264 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.299999999981
iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP
iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP
再用hping3验证此时80端口接发包正常。下面用curl命令检查Nginx对HTTP请求的响应:
curl --max-time 3 http://XXX.XXX.XXX.XXX
curl:(28) Operation timed out after 3000 milliseconds with 0 bytes received
这时候可以tcpdump转包来分析:
tcpdump -i eth0 -nn port 80
从结果中可以看出,前三个包是正常的TCP三次握手,但是第四个包确实在3s之后,并且还是客户端VM2发送来的FIN包,说明客户端的连接关闭了。因为curl命令设置了3s超时选项,所以这种情况是因为curl命令超时后退出。
重新执行netstat -i命令查看网卡有没有丢包问题,输出显示RX-DRP是344,即网卡接收时丢包了。但是之前hping3不丢包,现在换成curl GET却丢包,我们需要对比下这两个工具。
- hping3只发送SYN包
- curl在发送SYN包之后,还会发送HTTP GET 请求
HTTP GET本质上也是一个TCP包,但是和SYN包相比,它还携带了HTTP GET的数据。这时候就容易想到时MTU配置错误导致。查看eth0的MTU设置只有199,将其改为以太网默认值1500即可。
ifconfig eth0 mtu 1500
小结
遇到网络丢包问题,要从Linux网络收发的流程入手,结合TCP/IP协议栈的原理来逐层分析。
Lesson 49 案例篇:内核线程CPU利用率太高怎么办?
CPU使用率较高的内核线程,如果用之前的分析方法,一般需要借助于其他性能工具进行辅助分析。本节提供了一种直接观察内核线程的行为,更快定位瓶颈的方法。
内核线程
Linux中用户态进程的”祖先“都是PID为1的init进程,即systemd进程。但是systemd只管理用户态进程,那么内核态线程是有谁来管理呢?
- 0号进程为idle进程,系统创建的第一个进程,它在初始化1号和2号进程后,演变为空闲任务。
- 1号进程为init进程,即systemd进程,在用户态运行,用来管理其他用户态进程
- 2号进程为kthreadd进程,在内核态运行用来管理内核线程。
所以要查找内核线程,只需要从2号进程开始,查找它的子孙进程即可
ps -f --ppid 2 -p 2
#可以看出内核线程的名称都在中括号内,因此更简单的方法是直接查找名称中包含中括号的进程
ps -ef | grep '\[.*\]'
- ksoftirqd 软中断
- kswapd0, 用于内存回收
- kworker,用于执行内核工作队列,分为绑定CPU和未绑定CPU两大类
- migration,用于负载均衡中,把进程迁移到CPU上,每个CPU都有一个migration内核线程
- jbd2/sda1-8, Journaling Block Device,用来为文件系统提供日志功能,以保证数据的完整性
- pdflush,用于将内存中的脏页写入磁盘
实验
运行一个nginx容器,通过curl命令验证nginx服务正常开启。用hping3命令模拟Nginx客户端请求,此时回到第一个终端,发现系统响应变慢。
用top观察发现2个CPU上软中断使用率都超过了30%,正好是软中断内核线程ksoftirqd/0和ksoftirqd/1。对于内核线程我们用stace、pstack、lsof无法查看详细的调用栈情况,此时可以用内核提供的工具来分析。
perf record -a -g -p $pid --sleep 30
perf report
后续利用火焰图来协助排查分析定位热点函数,找出潜在的性能问题。
Lesson 50/51 案例篇:动态追踪怎么用?
动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮你分析、定位想要排查的问题。
Dtrace的工作原理:它的运行常驻在内核中,用户可以用dtrace命令,把D语言编写的追踪脚本,提交到内核中的运行时来执行。Dtrace可以跟踪用户态和内核态的所有事件,并通过一些列的优化措施,保证最小的性能开销。
Dtrace本身依然无法在Linux中运行,很多工程师都尝试过把Dtrace移植到Linux中,其中最著名的就是RedHat主推的SystemTap。
SystemTap也定义了一种类似的脚本语言,方便用户根据需要自由扩展。不过SystemTap没有常驻内核运行时,需要先把脚本编译为内核模块,然后再插入到内核中执行。因此systemTap启动比较慢,并且依赖于完整的调试符号表。
总的来说,为了追踪内核或用户空间的事件,Dtrace和SystemTap都会把用户传入的追踪处理函数,关联到被称为探针的检测点上。这些探针实际上也就是各种动态追踪技术所依赖的事件源。
根据事件类型不同,动态追踪所使用的事件源,可以分为静态探针、动态探针以及硬件事件三类。
- 硬件事件通常由性能监控计数器PMC产生,包含了各种硬件的性能情况,比如CPU的缓存、指令周期、分支预测等;
- 静态探针,是指实现在代码中定义好,并编译到应用程序或者内核中的探针。这些探针只有在开启探测功能时才会被执行到。
- 跟踪点 tracepoints,实际上就是在源码中插入的一些带有控制条件的探测点,这些探测点允许时候再添加处理函数。如内核中的printk
- USDT探针,全称时用户级静态定义跟踪,需要在源码中插入DTRACE_PROBE()代码,并编译到应用程序中。MYSQL/PostgreSQL也内置了USDT探针
动态探针,指没有事先在代码中定义,但却可以在运行时动态添加的探针。常见的动态探针都两种:
- kprobes用来跟踪内核态的函数,包括用于函数调用的kprobe和用于函数返回的kretprobe
uprobes用来跟踪用户态的函数,包括用于函数调用的uprobe和用于函数返回的uretprobe
kprobes需要内核编译时开启CONFIG_KPROBE_EVENTS,uprobes需要内核编译中开启CONFIG_UPROBE_EVENTS
动态追踪机制
在探针基础上,Linux也提供了一系列的动态追踪机制,比如ftrace、perf、eBPF等
- ftrace最早用于函数跟踪,后来又扩展支持了各种事件跟踪功能。
- perf是一种最简单的静态跟踪机制,也可以通过perf来定义动态事件,只关注真正感兴趣的事件
- eBPF是在BPF(Berkeley Packet Filter)的基础上扩展来的,不仅支持事件跟踪机制,还可以通过自定义的BPF代码
除此之外,还有很多内核外的工具,也提供了丰富的动态追踪功能,最常见的就是SystemTap和BCC,以及常用于容器性能分析的sysdig
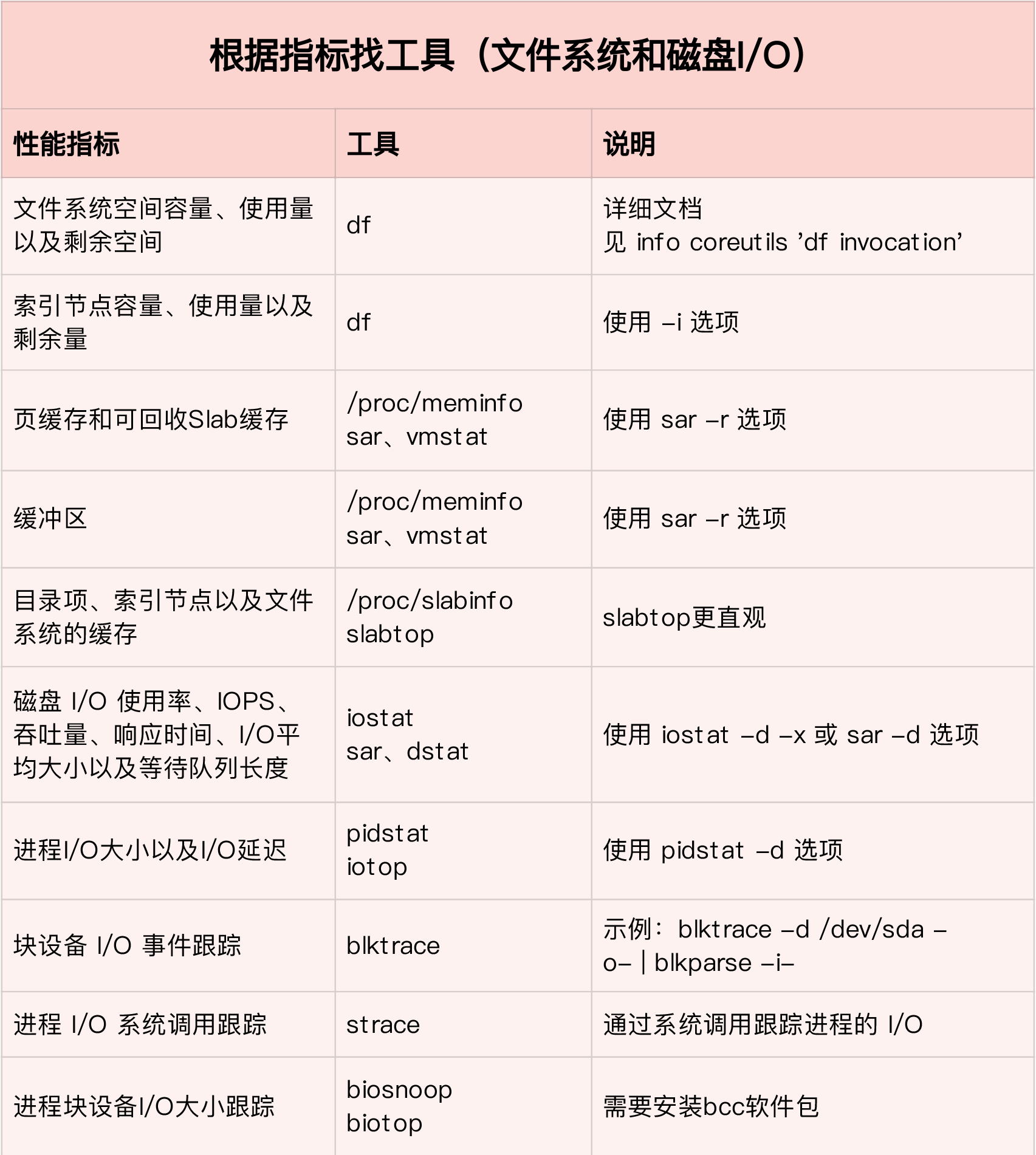
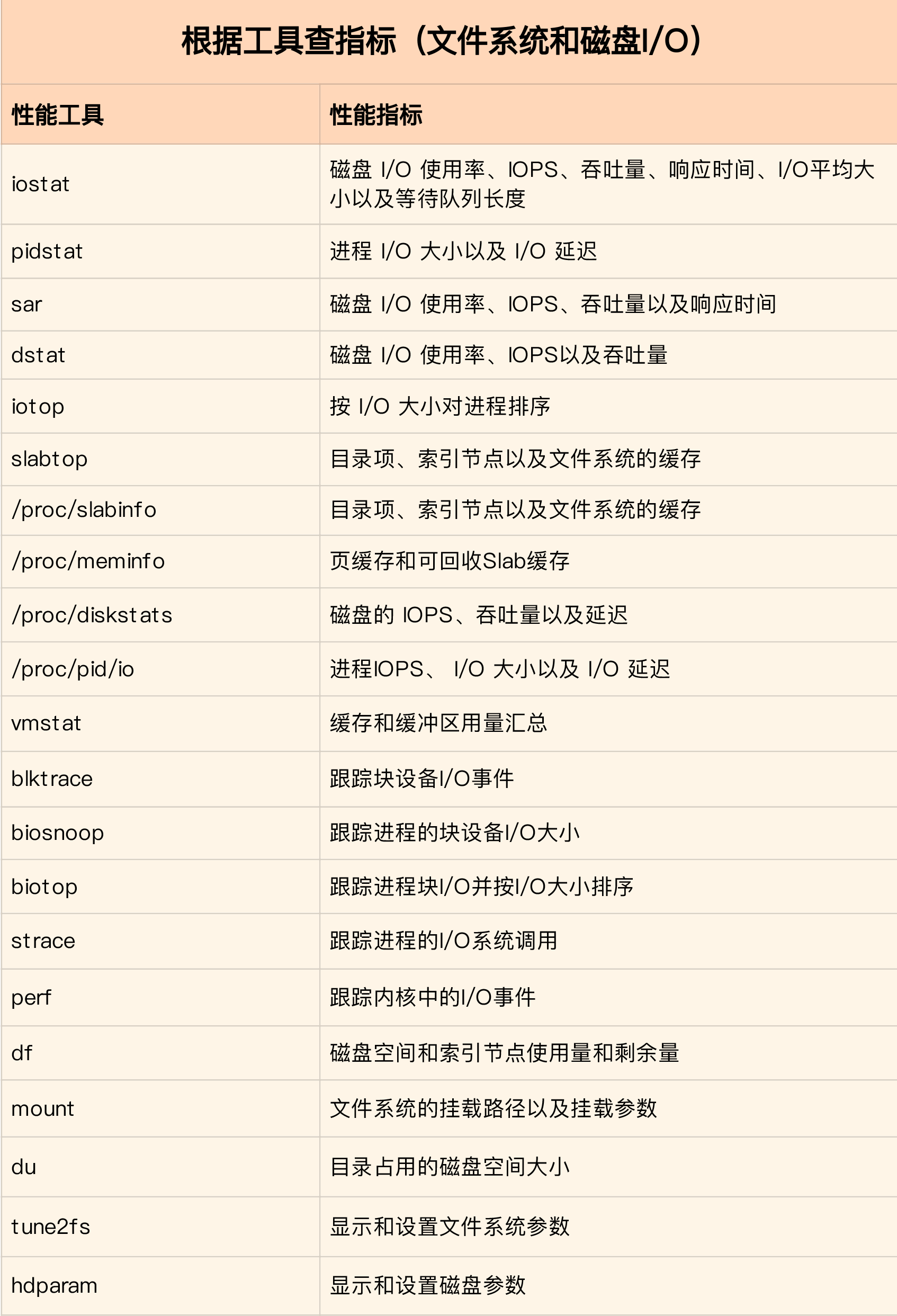
/performance_metric.png)
/cache.png)
/performance_tool.png)
/performance_tool_1.png)
/normal_tool.png)
/week1_1.png)
/LinuxPerformanceTool.png)