个人感悟
本周主要学习Linux I/O相关的基础知识以及遇到I/O异常问题如何分析解决。Linux一切皆文件。为了支持不同的文件系统,首先Linux在用户进程和文件系统之间实现了一层虚拟文件系统。用户进程和内核中的其他子系统只需要跟VFS提供的统一接口进行交互。其次,为了降低慢速磁盘对性能的影响,文件系统又通过页缓存、目录项缓存以及索引节点缓存来减少对应用程序性能的影响。
文件系统层、通用块层和块设备层组成了Linux存储系统I/O栈。其中通用块层是磁盘I/O的核心,向上为文件系统和应用程序提供访问块设备的标准接口,向下把各种异构磁盘抽象为统一的块设备,并对文件系统和应用程序发来的I/O请求进行重新排序、请求合并等。
通过实验学习了遇到IO瓶颈进一步导致CPU使用率高的问题如何分析和解决。一般通过iostat确认是否存在I/O性能瓶颈,再用strace和lsof定位应用程序以及它正在写入的日志文件路径。最后通过调整日志打印级别来解决。如果strace无法跟踪到write系统调用时,可以用filetop和opensnoop来定位具体的线程和读写文件目录;也可以加-p选项开启线程跟踪。
MYSQL的MyISAM引擎主要依赖系统缓存加速磁盘IO的访问。如果系统中还有其他应用同时运行,MyISAM引擎很难充分利用系统缓存。缓存可能会被其他应用程序占用,甚至被清理掉。因此最好不要将应用程序的性能优化完全建立在系统缓存上,最好能在应用程序内部分配内存,构建完全自主的缓存;或者利用第三方缓存应用,如Memcached,redis等。
对于磁盘IO瓶颈可以通过在内存充足时将数据放在更快的内存中来进行优化。也可以进一步利用Trie树等各种算法来进一步优化处理效率。
新工具GET
查看目录项和各种文件系统索引节点的缓存情况:
cat /proc/slabinfo | slabtop
磁盘IO观察
iostat -d -x 1 # -d -x 表示显示所有磁盘I/O的指标
进程IO观察
pidstat -d 1
iotop #可以按照I/O大小对进程排序找到I/O较大的进程
当strace无法跟踪到文件IO痕迹时
filetop 查看文件名以及使用情况
opensnoop 查看具体的文件目录
TCP网络连接可以用过nsenter工具来查看详细信息
思考
find / -name XXX 会不会导致系统的缓存升高?
会,导致inode_cache/dentry/proc_inode_cache/xfs_inode缓存升高
可以通过实验进行验证,先清除系统缓存,然后执行命令观察缓存使用情况。
iostat/pidstat已经证明了IO瓶颈是由哪个进程导致,为什么strace跟踪没有发现痕迹?
写文件是由子线程来进行处理的,默认strace是不开启线程跟踪的。在strace命令加上-fp选项既可以跟踪进程也可以跟踪线程。
接下来是本周读书笔记
Lesson 23 Linux文件系统是怎么工作的
- 磁盘为文件系统提供了最基本的持久化存储
- 文件系统在磁盘的基础上,提供了一个用来管理文件的树状结构
索引节点和目录项
Linux中一切皆文件。为了方便管理,Linux文件系统为每个文件都分配两个数据结构:
- 索引节点: index node,记录文件的元数据(如inode编号,文件大小,访问权限,修改日期,数据位置等)。索引节点会持久化存储到磁盘中,同样占用磁盘空间。
- 目录项: directory entry,记录文件的名字,索引节点指针以及与其他目录项的关联关系。目录项是由内核维护的一个内存数据结构,也叫目录项缓存。
索引节点是每个文件唯一标志,目录项维护文件系统的树状结构。目录项和索引节点关系是多对一。
磁盘在执行文件系统格式化时,会被分成三个存储区域:
- 超级块,存储整个文件系统的状态
- 索引节点区,用来存储索引节点
- 数据块区,用来存储文件数据
虚拟文件系统
目录项、虚拟节点、逻辑块以及超级块构成了Linux文件系统的四大基本要素,为了支持各种不同的文件系统,内核在用户进程和文件系统之间引入了一个虚拟文件系统VFS抽象层。
VFS定义了一组所有文件系统都支持的数据结构和标准接口。这样用户进程和内核中的其他子系统只需要跟VFS提供的统一接口进行交互即可。
文件系统I/O
根据是否利用标准库缓存,可以分为:
- 缓冲I/O,利用标准库缓存来加速文件的访问,标准库内部再通过系统调度访问文件
- 非缓冲I/O,直接通过系统调用来访问文件,不再经过标准库缓存
根据是否利用系统的页缓存,分为:
- 直接I/O,跳过操作系统的页缓存,直接跟文件系统交互来访问文件 (O_DIRECT)
- 非直接I/O,文件读写时,先要经过系统的页缓存然后再由内核或额外的系统调用,真正写入磁盘
根据应用程序是否阻塞自身运行,分为:
- 阻塞I/O,应用程序执行I/O操作后如果没有获得响应,就会阻塞当前线程
- 非阻塞I/O,应用程序执行I/O操作后,不会阻塞当前的线程,可以继续执行其他的任务。然后再通过轮询或者事件通知的形式获取调用结果 (O_NONBLOCK)
根据是否响应结果,分为:
- 所谓同步I/O,应用程序执行I/O操作后,要一直等到整个I/O完成后才能获得I/O响应 (O_SYNC/O_DSYNC)
- 所谓异步I/O,应用程序执行I/O操作后,不用等待完成和完成后的响应,而是继续执行就可以。等这次I/O完成后,响应会用事件通知的方式告诉应用程序 (O_ASYNC)
性能观测
cat /proc/slabinfo | grep -E '^#|dentry|inode'
slabtop
Lesson 24/25 Linux磁盘I/O时怎么工作的?
###磁盘
磁盘是可以持久化的设备,根据存储介质不同,分为:
- 机械磁盘(Hard Disk Driver),主要由盘片和读写磁头组成,数据存储在盘片的环状磁道中。读写数据时移动磁头,定位到数据所在的磁道中,然后才能访问。最小读写单位是扇区,一般512byte
- 固态磁盘(Solid State Disk),由固态电子元器件组成,不需要磁道寻址。无论连续I/O还是随机I/O都比前者要好。最小读写单位是页,一般4KB,8KB等
两种磁盘随机I/O都要比连续I/O慢得多:
- 机械磁盘随机I/O需要更多的磁头寻道和盘片旋转
- 固态磁盘同样存在“先擦除再写入的限制”,随机读写会导致大量的垃圾回收
- 连续I/O可以通过预读的方式来减少I/O请求的次数
###通用块层
通用块层,是处在文件系统和磁盘驱动中间的一个块设备抽象层。主要有以下功能:
- 与VFS类似,向上为文件系统和应用程序提供块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
- 给文件系统和应用程序发来的I/O请求排队,并通过重新排序、请求合并等来提升磁盘读写的能力。
I/O调度算法:
- NONE,不使用任何I/O调度,常用在虚拟机中
- NOOP,先入先出队列,只进行最基本的请求合并,常用与SSD磁盘
- CFQ(Completely Fair Schedule),完全公平调度器,为每个进程维护一个I/O调度队列,并按照时间片来均匀分布每个进程的I/O请求。 类似进程CPU调度,CFQ还支持进程I/O的优先级调度,适用于大量进程的系统
- Deadline,分别为读写请求创建不同的I/O队列,提高机械磁盘的吞吐量,并确保达到最终期限的请求被优先处理。多用于IO压力较重的场景,如数据库等
IO栈
Linux存储系统的I/O栈由上到下分为 文件系统层、通用块层、设备层。存储系统的IO通常是整个系统最慢的一环,所以Linux系统通过多种缓存机制来优化I/O效率。
- 优化文件访问性能: 页缓存、索引节点缓存、目录项缓存等减少对下层设备的直接调用
- 优化块设备访问性能:使用缓冲区来缓存块设备的数据
磁盘性能指标
- 使用率, 磁盘处理I/O的时间百分比
- 饱和度, 磁盘处理I/O的繁忙程度
- IOPS, 每秒的I/O请求数
- 吞吐量, 每秒I/O请求大小
- 响应时间, I/O请求从发出到收到响应的间隔时间
磁盘I/O观测
iostat -d -x 1 # -d -x 表示显示所有磁盘I/O的指标
进程I/O观测
pidstat -d 1
iotop #可以按照I/O大小对进程排序找到I/O较大的进程
Lesson 26 案例篇:如何找出狂打日志的内鬼
实验
首先运行目标应用
sudo docker run -v /tmp:/tmp --name=app -itd feisky/logapp
ps -ef | grep /app.py #确保程序启动
我们先用top来观察CPU和内存的使用情况,然后再用iostat来观察磁盘使用情况
top
#观察发现CPU0使用率高且iowait超过了90%,说明cpu0上正在运行IO密集型程序
#进程方面pythonCPU使用率较高,记录其pid号
#内存使用方面,总内存8G剩余700+M,Buffer/Cache占用较高
基本可以判断出CPU使用率中的iowait是一个潜在瓶颈,而内存中的缓存占比较大。
再用iostat查看I/O使用情况
iostat -x -d 1
#发现sda的I/O使用率很高,很可能已经接近饱和
#查看前面指标,每秒写磁盘请求数是64,写大小是32MB,写请求响应时间7s,而请求队列长度则达到了1000+
#超慢的响应时间和请求队列过长,进一步验证了IO已经饱和
接下来分析I/O性能瓶颈的根源
pidstat -d 1
#此时python进程的写比较大,且每秒数据超过了45M,说明python进程导致了IO瓶颈
strace -p XXXX
#在write()系统调用上,可以看出进程向文件描述符编号为3的文件中写入了300M数据
#再观察后面的stat调用,可以看到它正在获取/tmp/logtest.txt.1的状态,这种格式的文件在日志回滚中常见
losf -p XXXX
#查看进程打开了哪些文件,/tmp/logtest.txt
综上说明进程以每次300MB的速度在疯狂的写日志,其中日志文件目录为/tmp/logtest.txt。此时查看案例源码发现其默认记录INFO级别以上的所有日志。此时将默认级别调高到WARNING级别,日志问题即可解决。
Lesson 27 案例篇:为什么我的磁盘IO延迟很高?
实验
本实验需要两台虚拟机,一台案例分析的目标机器运行Flask应用,另一台作为客户端请求单词的热度。
sudo docker run --name=app -p 10000:80 -itd feisky/word-app
然后在第二天机器 curl */popularity/word 发现一直没响应
回第一台机器来分析,首先执行df命令查看文件系统使用情况,发现也要等好久才输出。此时df显示系统还有足够多的磁盘空间。此时同样可以先用top来观察CPU和内存使用情况,再用iostat来观察磁盘的IO情况。
为了避免curl请求结束,在终端2循环执行curl,并用time观察每次执行时间。
while true; do
time curl */popularity/word
sleep 1
done
top输出发现两个CPU的iowait都非常高,进程部分python进程的CPU使用率稍高,可能和iowait相关。 记录其pid
ps -aux | grep app.py #正好CPU使用率高的进程是我们的案例应用
iostat -x -d 1 #发现磁盘sda的I/O使用率已经达到98%,写响应时间18s,每秒32MB显然已经达到了IO瓶颈
pidstat -d 1 #再次看到了案例应用pid导致的io瓶颈
strace -p XXX
类似上节的套路,此时strace中可以看到大量的stat系统调用,却没有任何write调用。文件写明明应该有响应的write系统调用,现有工具却找不到痕迹。此时就该考虑换工具了,filetop基于eBPF机制,主要跟踪内核中文件的读写情况,并输出线程ID、读写大小、读写类型以及文件名称。
filetop -C #发现每隔一段时间线程号为XXX的python应用会写入大量的txt文件,再大量读。
ps -efT | grep XXX #该线程确实属于我们的应用进程
filetop只给出文件名,并没有给出文件路径。此时opensnoop工具登场
opensnoop #可以看到这些txt文件位于/tmp目录下,文件从0.txt到1000.txt
结合filetop和opensnoop我们可以猜测案例应用应该是写入1000个txt文件后,又将这些文件内容读取到内存中进行处理。在打断ls检查路径中文件时发现内容为空。此时再次运行opensnoop发现目录变化了,说明这些目录都是应用程序动态生成的,用后就删除了。
接下来查看程序源码发现该案例应用,在每个请求的处理过程中都会生成一批临时文件,然后读入内存处理,最后再删除整个目录。这是一种常见的利用磁盘空间处理大量数据的技巧,不过本次案例中的IO请求太重导致磁盘I/O利用率过高。
通过算法优化,在内存充足时将所有数据放到内存中处理,这样就能避免IO性能问题。
Lesson 28 案例篇:一个SQL查询要15s是怎么回事?
实验
案例由3个容器组成,一个mysql数据库应用,一个商品搜索应用,一个数据处理的应用。在执行搜索命令时遇到了返回数据为空且处理时间超过15s的问题。同样通过循环持续发送请求来进行问题问题,为了避免系统压力过大sleep 5s再开始新请求。
同样的套路,top iostat pidstat定位IO瓶颈问题以及mysqld进程。慢查询现象大多是CPU使用率高,但这里看到的却是IO问题,说明这并不是单纯的慢查询问题。
接下来通过strace发现线程XXX正在读取大量数据,且读取文件的描述符编号为38。再用lsof尝试查找对应的文件,此时发现lsof没有任何输出。
echo $? #查找上一条指令退出时返回值,结果为1说明lsof命令执行失败。
因为-p需要指定进程号,而我们传入线程号所以执行失败。
切换回进程号重新执行lsof命令,从输出可以看出确实mysqld进程打开了大量的文件,根据文件描述符找到对应的文件路径为/var/lib/mysql/test/products.MYD文件。
MYSQL中MYD文件时MyISAM引擎用来存储表数据的文件,文件名就是数据表的名字,父目录即为数据库的名字。 即改文件告诉我们mysqld正在读取test数据库中的products表。
如何确定这些文件是不是mysqld正在使用的数据库文件呢?有没有可能是不再使用的旧数据?我们通过查看mysqld配置的数据路径即可。
sudo docker exec -ti mysql mysql -e 'show global variable like "%datadir%";'
可以看到/var/lib/mysql确实是mysqld正在使用的数据存储目录。
即然找出了数据库和表,下一步就是弄清楚数据库中正在执行什么样的SQL。
在SQL命令界面执行
show full processlist #可以看到select * from products where productName=‘geektime’这条执行时间比较长
一般SQL慢查询问题,很可能是没有利用好索引导致,如何判断这条是不是这样?
explain select * from products where productName-‘geektime’
其中pissible_keys和key都为NULL,type为ALL全表查询,这条查询语句根本没有使用索引,所以查询时会扫描整个表。
因此给productName建立索引即可, 优化后查询时间从15s缩短到了3ms。
该案例中测试时启动了一个DataService应用,其实停止该应用查询时间也能缩短到0.1s。这种情况下是否还存在IO瓶颈呢?通过vmstat来查看IO变化,发现磁盘读和iowait刚开始挺大,但是没过多久就变成了0,说明IO瓶颈消失。为什么呢?
通过查看DataService源码可以看到其读取文件前先将 /proc/sys/vm/drop_caches改为1。即释放文件缓存,而mysql读取的数据就是文件缓存,dataService不断释放缓存导致mysql直接访问磁盘。因此产生IO瓶颈。
Lesson 29 案例篇:Redis响应验证延迟,如何解决?
实验
本实验由python应用和redis两部分组成。Python应用是一个基于Flask的应用,会利用Redis来管理应用程序的缓存。
实验中在访问应用程序的缓存接口时,发现10s的长响应时间,接下来定位瓶颈。
同样为了避免分析过程中请求结束,通过loop循环来执行curl命令。
继续先通过top和iostat先分析是否存在IO瓶颈。 结果发现CPU的iowait比较高,但是磁盘每秒写数据为2.5M,IO使用率为0,没有IO瓶颈。
但是案例中测试时从Redis缓存中读取数据,对应应该时磁盘的读操作,iostat结果却显示时写操作。所以我们就要知道是什么进程在具体写磁盘。
运行pidstat -d查看发现是redis-server进程在写磁盘。接下来用strace+lsof查看到底在写什么。从系统调用看epoll_wait、read、write、fdatasync这些系统调用都比较频繁,刚才观察的写操作应该是write和fdatasync导致。lsof找出这些系统调用的操作对象,发现只有7号普通文件会产生磁盘写,其操作路径为/data/appendonly.aof。
在Redis中这对应着持久化配置中的appendonly和appendfsync选项,可能是由于它们配置不合理导致磁盘写较多。为了验证这个猜测,通过redis命令行查这两个选项的配置。
sudo docker exec -ti redis redis-cli config get 'append*'
发现appendfsync配置为always,appendonly配置为yes。
Redis提供了两种数据持久化方式:
- 快照方式,按照指定的时间间隔生成数据的快照,并且保存在磁盘文件中。为避免阻塞主进程,Redis会fork一个子进程来进行快照的保存。 无论备份恢复都比追加文件性能好,缺点是在数据量大时fork子进程会用到比较大的内存,保存数据比较耗时。
- 追加文件,在文件末尾追加记录的方式对redis写入数据进行持久化。提供appendfsync选项设置fsync策略:
- always, 每个操作都会执行一次fsync,最安全
- everysec,每秒钟调用一次fsync,即使最坏情况也只会丢失1s数据
- no, 交给操作系统来处理
回头看上述测试,因为配置为always导致每次写数据都会调用一次fsync,从而造成比较大的磁盘IO压力。
但是为什么查询会有磁盘写呢,我们再次审视strace和lsof的输出,发现编号为8的TCP socket正好对应TCP读写,是一个标准的“请求-相应”格式。从socket中GET uuid:X后响应good,再从socket中读取SADD good X后响应1。对Redis来说SADD是一个写操作,所以Redis会将其持久化到appendonly.aof文件中。因此产生大量的磁盘读写。
接下来我们确认8号TCPsocket对应的Redis客户端是否为我们的案例应用。 通过lsof -i 找出TCP socket对应的TCP连接信息,进入容器网络命名空间内部看到完成的TCP连接。
PID=$(sudo docker inspect --format {{.State.Pid}} app)
nsenter --target $PID --net -- lsof -i
综合分析可知,首先redis配置always不太合理,本案例不需要这么高频的同步写,改为1s时间间隔足够;其次python应用在查询接口中会调用Redis的SADD命令,这很可能是不合理使用缓存导致。
修改配置后请求时间降低到0.9s,接着通过分析源码解决第二个问题。代码中Python应用将Redis当成临时空间,用来存储查询过程中找到的数据。优化将其放在内存中,再次查看响应时间已经降低到了0.2s。
Lesson 30 套路篇:如何迅速分析出系统IO瓶颈
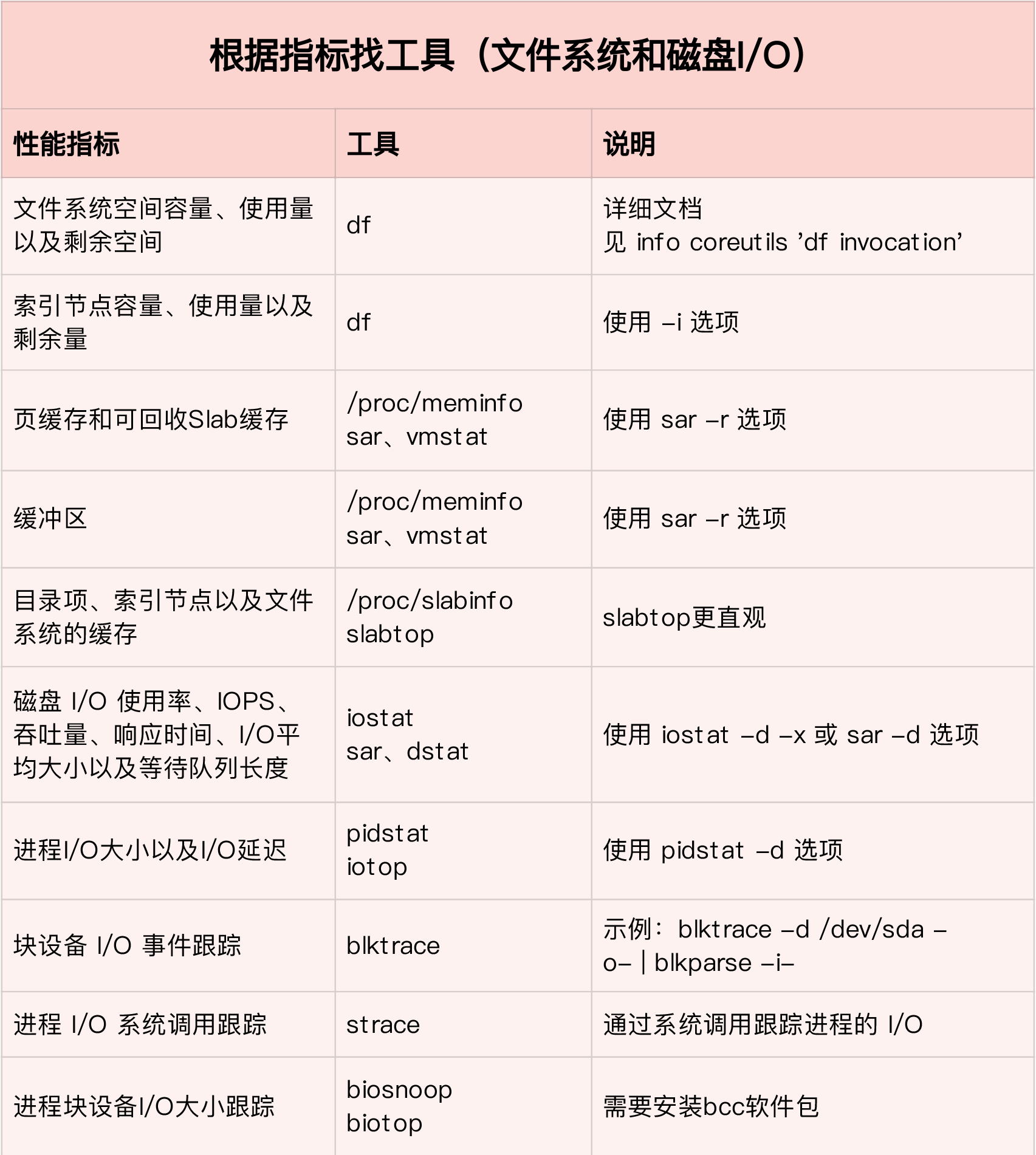
性能指标
文件系统IO性能指标
- 存储空间的使用情况,容量、使用量以及剩余空间等
- 文件系统向外展示的空间使用,而非磁盘空间的真实用量
- 索引节点的使用情况,包括容量、使用量以及剩余量 (如果文件系统中存储过多的小文件,就能碰到索引节点容量已满的问题)
- 缓存使用情况,页缓存、目录项缓存、索引节点缓存以及各个具体文件系统的缓存
- 文件系统IO, IOPS、响应延迟时间、以及吞吐量
Linux文件系统并没有提供直接查看这些指标的方法,只能通过系统调用、动态跟踪或者基准测试的方法来间接观察评估。
磁盘IO性能指标
- 使用率
- IOPS
- 吞吐量
- 响应时间
- Buffer也常出现在内存和磁盘问题的分析中
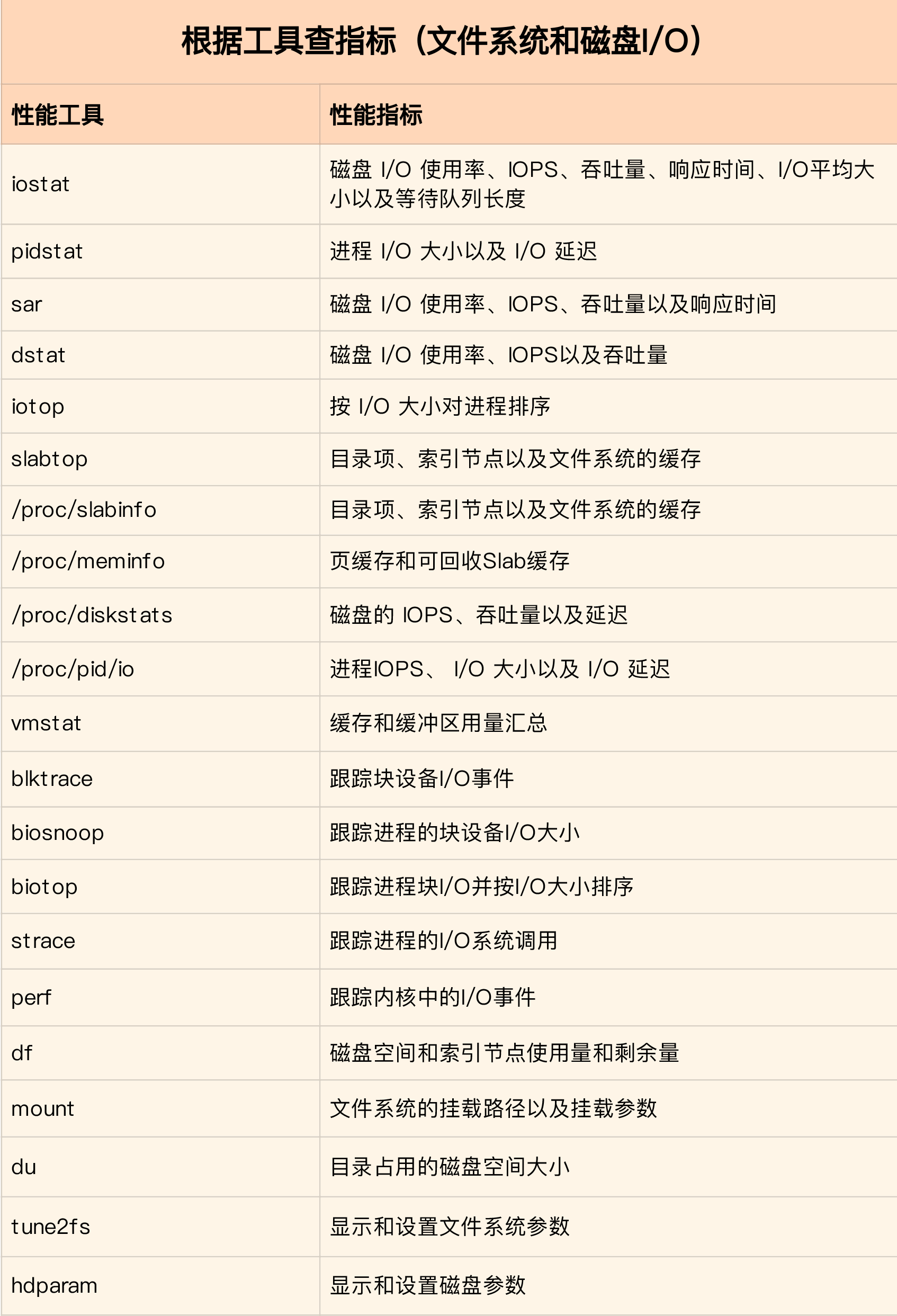
性能工具
- df,既可以查看文件系统数据的空间容量,也可以查看索引节点的容量
- /proc/meminfo,/proc/slabinfo及slaptop,观察页缓存、目录项缓存、索引节点缓存以及具体的文件系统的缓存
- iostat,pidstat观察磁盘和进程的IO情况
- iostat查看磁盘的IO使用率、吞吐量、响应时间以及IOPS性能指标
- pidstat查看进程的IO吞吐量以及块设备的IO延迟
- strace+lsof定位问题进程正在读写的文件
- filetop+opensnoop,从内核中跟踪系统调用,最终找出瓶颈来源
性能指标和工具的联系
根据指标找工具
根据工具查指标
如何迅速分析I/O的性能瓶颈
- 先用iostat发现磁盘IO性能瓶颈
- 再借助pidstat定位出导致瓶颈的进程
- 随后分析进程的IO行为
- 最后结合应用程序的原理,分析这些IO的来源
为了缩小排查范围,通常先运行几个支持指标较多的工具,如iostat、vmstat、pidstat等,然后再根据观察到的现象,结合系统和应用程序的原理,寻找下一步的分析方向。
例如MYSQL和Redis案例中,通过iostat确认磁盘出现IO性能瓶颈,然后用pidstat找出I/O最大的进程,接着借助strace找出该进程正在读写的文件,最后结合应用程序的原理找出大量IO的原因。
当用iostat发现磁盘IO性能瓶颈后,再用pidstat和vmstat检查,可能会发现IO来自内核线程。如Swap使用大量升高。这种情况下,就得进行内存分析,先找出占用大量内存的进程,再设法减少内存的使用。
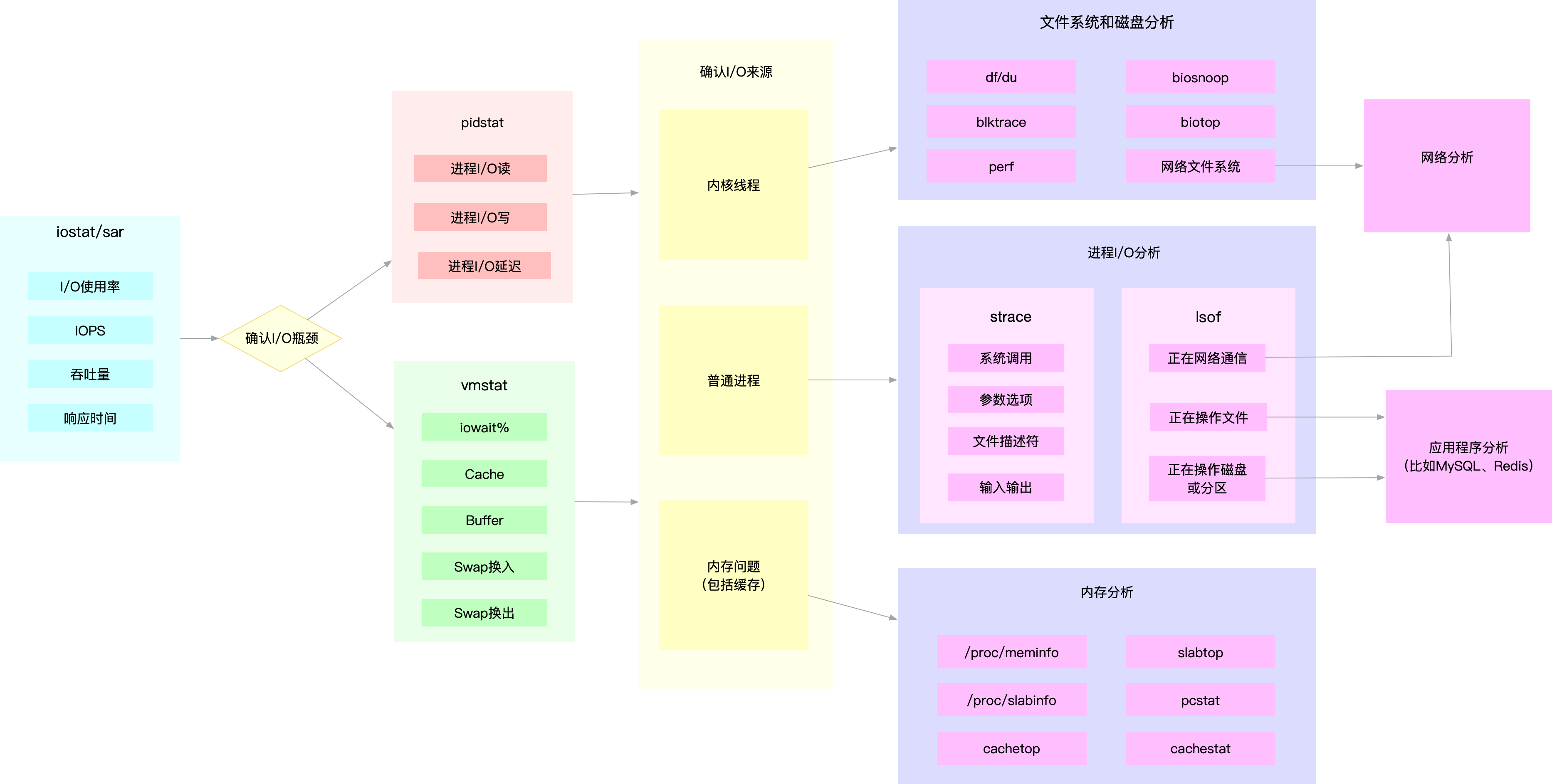
Lesson 31 套路篇: 磁盘I/O性能优化的几个思路
IO基准测试
为了更客观的评估优化效果,首先应该对磁盘和文件系统进行基准测试,得到文件系统或磁盘IO的极限性能。
fio(Flexible I/O Tester)是最常用的基准测试工具
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
#顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
#顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
- direct表示是否跳过系统缓存,1表示跳过
- iodepth表示使用异步I/O(asynchronous I/O)时同时发出的IO请求上限
- rw表示I/O模式
- ioengine表示I/O引擎,支持同步sync,异步libaio,内存映射mmap,网络net等
- bs表示I/O的大小
结果报告中
- slat表示从I/O提交到实际执行I/O的时长。 submission latency
- clat表示从I/O提交到I/O完成的时长。 completion latency
- lat表示从fio创建IO到IO完成的总时长
fio支持I/O的重放,先用blktrace记录磁盘设备的I/O访问情况,然后使用fio重放blktrace的记录。
blktrace /dev/sdb #跟踪磁盘IO
ls #查看blktrace记录的结果
blkparse sdb -d sdb.bin #将结果转化为二进制文件
fio --name=reply --filename=/dev/sdb --direct=1 --read_iolog=sdb.bin #使用fio重放日志
I/O性能优化
应用程序优化
- 可以用追加写代替随机写,减少寻址开销,加快I/O写的速度
- 可以借助缓存I/O,充分利用系统缓存,降低实际I/O的次数
- 在应用程序内部构建自己的缓存,或者用Redis等外部缓存。一方面能在应用程序内部控制缓存的数据和生命周期,另一方面可以降低其他应用程序使用缓存对自身的影响
- 需要频繁读写同一块磁盘空间时,可以用mmap代替read/write,减少内存的拷贝次数
- 在需要写同步的场景中,尽量将写请求合并,即可以用fsync()取代O_SYNC
- 在多个应用程序共享磁盘时,为了保证I/O不被某个应用完全占用,推荐使用cgroups的I/O子系统来限制进程/进程组的IOPS以及吞吐量
- 在使用CFQ调度器时,可以用ionice来调整进程的调度优先级,提高核心应用的I/O优先级。
文件系统优化
- 根据实际负载场景不同选择最适合的文件系统
- 选好文件系统后进一步优化文件系统的配置选项,包括文件系统的特性、日志模式、挂载选项等
- 优化文件系统的缓存
- 不需要持久化时可以用内存文件系统tmpfs来获取更好的IO性能。
磁盘优化
- 换用性能更好的磁盘, 如SSD替换HDD
- 使用RAID将多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。既可以提高数据的可靠性,又可以提升数据的访问性能
- 针对磁盘和应用程序IO模式特征,选择最合适的IO调度算法
- SSD和虚拟机中的磁盘,用noop调度算法
- 数据库应用,用deadline算法
- 对应用程序的数据进行磁盘级别的隔离。 为日志、数据库等I/O压力大的应用配置单独的磁盘
- 顺序读多的场景增大磁盘的预读数据
- 调整内核选项/sys/block/sdb/queue/read_ahead_kb, 默认为128KB
- blockdev工具设置, blockdev –setra 8192 /dev/sdb, 这里单位为512B
- 优化块设备的I/O选项
- 调整磁盘队列的长度,/sys/block/sdb/queue/nr_requests
最后要注意磁盘本身是否存在硬件错误。 可以查看dmesg中是否有硬件I/O故障的日志。还可以用badblocks、smartctl等工具检测磁盘的硬件问题,或者用e2fsck来检测文件系统的错误。 如果发现问题可以用fsck来修复。
Lesson 32 答疑 (略)
捞评论学习:
- 数据写ES,运行一段时间后发现写入很慢,查IO时发现读IO很高写IO很少。用iotop定位es一些写的线程,将线程id转成16进制,用jstack打印出ES的堆栈信息,查处16进程的线程号的堆栈。发现原来时ES会根据doc id查数据,然后选择更新或新插入。ES数据量大时,会占用很多的读IO。 解决方法:写ES时不传入id,让es自动生成来解决。