K8S学习之——ETCD
Etcd is distributed reliable key-value store for the most critical data of a distributed system, with a focus on being:
- Simple: well-defined, user-facing API (gRPC)
- Secure: automatic TLS with optional client cert authentication
- Fast: benchmarked 10,000 writes/sec
- Reliable: properly distributed using Raft
简单来说etcd是kubernetes提供默认的存储系统,通过分布式KV存储来保存集群中重要的数据,因此我们使用时需要为etcd数据提供备份计划。
Etcd is written in Go and uses the Raft consensus algorithm to manage a highly-available replicated log.
它通过raft一致性算法来实现可靠的分布式存储,我们上个月在team meetup中也是主要探讨了raft算法原理以及它与zookeeper的一些区别,在此通过本文记录下。
Raft算法原理
Raft算法和zookeeper类似,都是通过大多数机制来保证一致性。在Raft算法中通过选举出来的leader节点来接收客户端的请求日志数据,然后同步到集群中其它节点进行复制,当日志已经同步到超多半数以上节点的时候,该日志状态变为committed可提交状态,即可以提交到状态机中执行。此外leader节点还要通知其他节点哪些日志已经被复制成功。
Raft算法将要解决的一致性问题分为以下三个子问题:
- leader选举: 通过心跳机制来触发leader选举,保证集群中存在一个leader节点
- 日志复制: leader节点将来自客户端的请求序列化成日志数据并且同步复制到其它节点
- 安全性: 如果某个节点已经将一条日志数据提交到状态机中执行,那么其他节点不可能再将此条数据输入到状态机中重复执行。
Raft算法需要保证以下几个特性:
- Election Safety:在一个任期内最多只能存在一个leader节点
- Leader Append-Only:leader节点只能添加日志数据,不会删除/覆盖以前的数据
- Log Matching:如果两个节点的日志在某个索引上的日志数据和任期号都相同,那么在此index之前的日志数据一定也匹配
- Leader Completeness:如果一条日志在某个任期被提交,那么该条日志数据在leader节点上更高任期号的日志数据中一定存在。
- State Machine Safety:一条提交到raft状态机执行过的数据不可能再被其他节点提交执行。
Leader选举
Node节点状态
- Leader: 领导者,一个集群中只能存在一个leader
- Follower:跟随者,一个客户端的操作请求发送到follower上面,会首先由follwer重定向到leader上
- Candidate:参与者,在此状态的节点会发起新的选举
节点状态切换如图所示
- 所有节点启动时自动进入Follower状态
- Follower节点启动时会开启一个选举超时的定时器,当times out时节点切换到Candidate状态发起选举
- 节点一旦转换为Candidate状态就开始进行选举,如果在下一次选举超时到来之前都没有选出Leader节点,那么节点会保持状态不变重新发起一次新的选举
- 若Candidate节点收到集群中超过半数的节点选票(包含自身),那么状态切换到Leader
- 若Candidate节点接收到来自Leader节点的消息,或者任期号更高的消息,即集群中已经存在Leader节点,此时节点状态切换回Follower
- Leader节点如果收到来自更高任期号的消息则切换回Follower节点(常见网络分区场景下)
其中节点之间的通信通过RPC来完成,etcd中主要由两种RPC请求:
- RequestVote 用于Candidate节点发起选举
- AppendEntries 用于Leader节点向其他节点进行复制日志数据,以及同步心跳
Raft算法通过心跳机制来触发Leader选举
节点启动时状态为Follower,只要一直接收到来自Leader或者Candidate的正常RPC消息,就会一直保持为Follower状态。
Leader节点周期性的向其它节点发送心跳请求来保持Leader状态,其中心跳请求即带有空数据的AppendEntries。
每个Follower节点都有一个选举超时定时器,如果在超时之前都没有接收到Leader的心跳请求将发起选举。发起选举时,Follower将自身的任期号+1并且切换到Candidate状态,然后向集群中其它节点发送RequestVote请求进行选举。
Candidate节点保持状态不变,直到以下情况之一发生:
- 该节点收到集群中半数以上的节点投票,即赢得选举;
- 节点收到来自Leader节点的数据;
- 选举超时到来
第一种情况,因为每个Follower节点在一个任期内只能给一个节点投票先来先到,通过大多数原则保证了每个任期最多只有一个节点赢得选票(存在无节点当选的情况)。当节点成为Leader后会向集群中其它节点发送心跳消息来阻止不必要的选举。
第二种情况,处于Candidate状态下的节点收到了来自其它节点的心跳/AppendEntries消息。如果AppendEntries请求中的任期号大于自身任期,说明集群中已经存在Leader节点,此时节点转换成Follower状态。反之如果消息中任期号小于自身,则拒绝该消息,继续保持节点状态不变。
第三种情况,在选举超时到来时该节点没有赢得选举且没有收到其它节点的AppendEntries消息,说明集群中没有Leader存在,该Candidate节点任期号+1,再次发起选举。
其中,第三种情况发生在集群节点为偶数个,且有两个Candidate节点同时选举。理论上这种无法选择Leader的情况可以无限循环下去。为了避免该情况,每个节点的选举超时时间通过随机函数决定,一般在150ms-300ms之间。 (我们也仔细讨论了这种情况,因为Leader发送心跳消息时间非常短暂,如果节点选举超时时间T都相同,Leader节点挂掉那么可以极端得考虑认为所有Follower节点会在同一时刻(距离上一个心跳消息T时间)得到该信息。此时会有很多Follower节点切换到Candidate状态并进行选举,任意一个节点获得大多数投票的概率都很低。 而如果每个节点的超时时间是个随机值,那么大概率集群中有一个超时时间短的节点先感知到原Leader挂掉的事实,然后首先发起选举,因为RPC消息时间耗时较短,该节点大概率能获得大多数投票。)
日志复制
日志形式
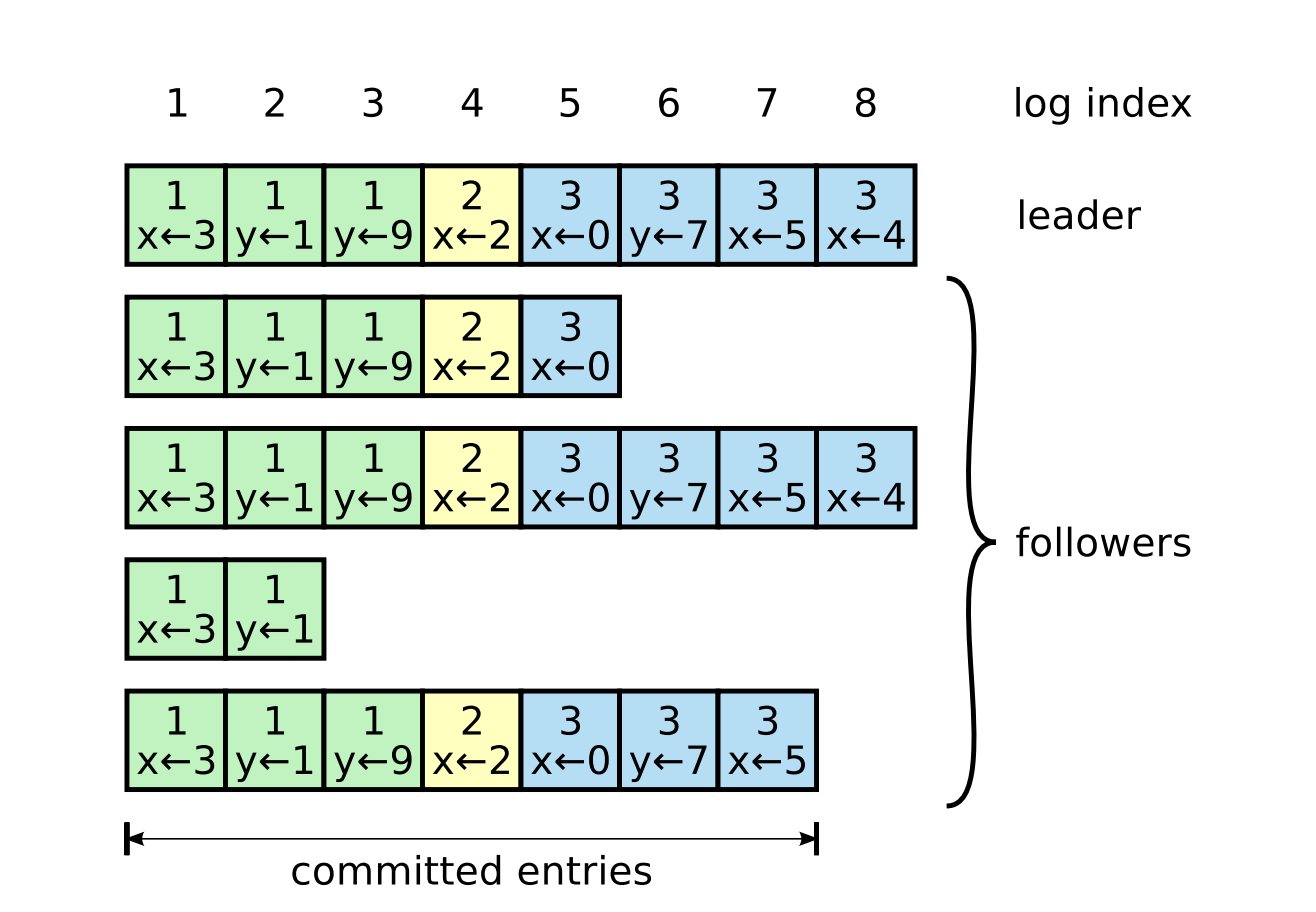
如上图所示,日志主要由以下三个成员组成:
- index:索引号,即图中最上方的数字
- term:任期号,每个日志条目中上方数字,表示该日志在哪个任期中生成
- command:日志中的数据修改操作
如果一条日志被Leader节点同步到超过半数的节点中,被称为“成功复制”,这个日志条目就是committed状态(已经被提交)。如果某条日志条目状态为committed,那么在此日志之前的所有日志也都是committed状态。(如图中index<=7的日志都是committed状态)
committed状态的日志可以被Leader输入到raft状态机中执行,执行过的日志状态为applied。
日志复制过程



- 首先客户端的消息转发到集群Leader节点上
- Leader节点首先在本地日志中添加一条日志
- Leader节点通过AppendEntries RPC消息的形式向集群中其它节点广播该日志
- Follower节点收到日志首先也同样在本地日志中添加一条日志
- Follower节点向Leader节点返回AppendEntries应答消息
- Leader节点收到超过半数的应答消息时认为该日志已经被成功复制,将本地的committedIndex指向该日志的index
- 如果该committed状态的日志被提交到状态机中执行,那么Leader节点本地日志中的appliedIndex也要随之更新
- Leader节点在下次广播AppendEntries消息时会带上最新的committedIndex和appliedIndex,用于Follower节点本地日志的索引更新。
日志恢复过程
正常情况下Follower节点和Leader节点的日志会始终保持一致,但是当Leader节点突然挂掉时集群中节点日志会出现不一致的情况,当新的Leader选举出来后就需要进行相应的恢复操作。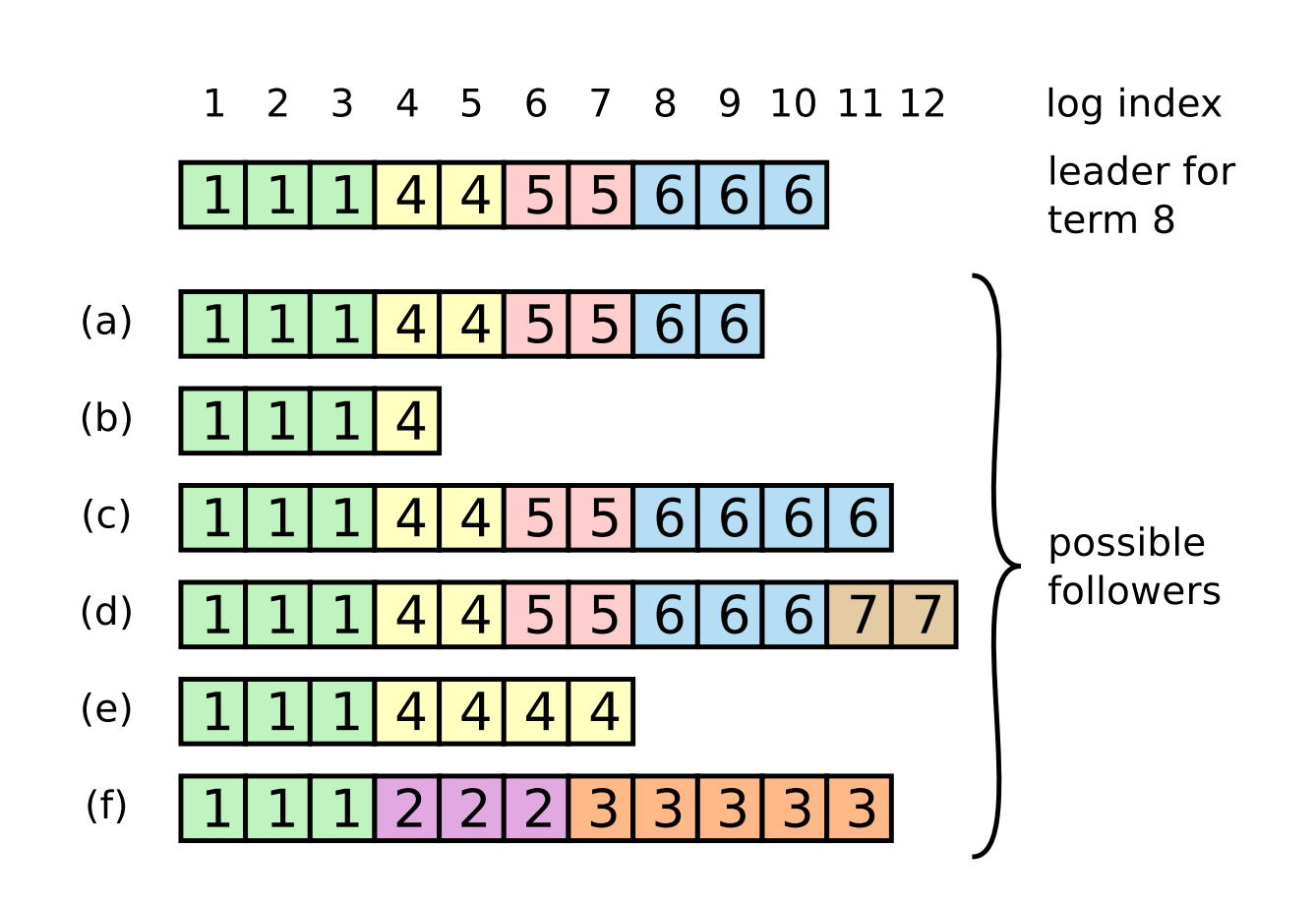
Raft算法通过Leader节点同步来解决数据不一致问题。 对于集群中任意一个节点,Leader中都存储着两个与它们日志相关的数据。
- nextIndex: 下一次向该Follower节点同步时的日志索引
- matchIndex: 该Follower节点的最大日志索引
在Follower节点和Leader节点日志复制正常的情况下,nextIndex = matchIndex + 1。如果日志不一致情况出现那么该等式不成立。
集群中原Leader宕机,新Leader选出后将初始化nextIndex为新Leader节点的最后一条日志索引,matchIndex均为0。这样做的目的是首先从Follower节点的最后一条日志进行探索,如果不匹配则从前向后进行复制。
如上图所示,Leader节点存储每个Follower节点的nextIndex=10,matchIndex=0。成为Leader首次向其它节点复制日志时,会复制index>=10的日志,同时带上2⃣️元组<6,10>告知Follower节点将要复制Term=6,index=10的日志数据。
- 只有(a)节点的最大日志数据2⃣️元组<6,9>和Leader传来的<6,10>紧邻,复制成功且matchIndex也随之更新。
- 其他几个节点的2⃣️元组都不匹配,返回复制失败。Leader节点收到拒绝消息后修改该follwer节点的索引数据,将nextIndex复制为matchIndex+1即1。下次同步时从索引1到10的数据给该Follwer节点,且Follower节点中未提交的数据被清除。
安全性
Raft算法对选举进行限制来保证安全性。
- 一个节点向成为Leader就必须得到集群中超过半数的选票
- 节点A投票给另一个节点B的必要条件时B的日志比A的要新(首先对比任期号,相同时再比较索引)
Raft算法处理只读请求
一般情况下,客户端的命令需要经过日志复制过程,当集群超过半数节点应答之后才可以提交给状态机执行,执行结束后再应答给客户端。这样的流程对于只读数据来说太漫长,如果不经过这样的流程Leader节点直接将本节点上保存的数据返回给客户端又是不安全的,因为可能返回的数据已经过期。因此Raft中针对只读请求有特殊的高效处理:
- Leader节点需要有当前已提交的日志数据。如果该节点新成为Leader需要提交一个dummy空日志来确保上一个任期的日志全部提交。
- Leader节点保存该只读请求到来时的committedIndex为readIndex
- Leader节点确认自己是否还是集群中的leader(广播心跳给集群中节点,收到半数以上应答即可判断)同时readIndex索引也是当前集群日志AppliedIndex的最大索引
- 读取Leader节点中数据
——————————————————————————————————————————————————————————————————
LastModify:2019-06-18