个人感悟
在实际的性能分析中,发生性能瓶颈后登陆服务器想要排查的时候发现瓶颈已经消失且很难复现。因此要事先搭建监控系统,把系统和应用程序的运行状况监控下来,并定义一系列的策略,在发生问题第一时间告警处理。
系统监控通过USE法则利用prometheus+grafana来监控系统资源。应用程序监控分为指标监控和日志监控两大块,在复杂业务场景中通常搭建全链路跟踪系统来定位应用瓶颈。
性能问题可以从系统资源瓶颈和应用程序瓶颈两个角度来梳理分析。系统时应用的运行环境,系统的瓶颈会导致应用的性能下降,而应用的不合理设计也会引发系统资源的瓶颈。做性能分析要结合应用程序和操作系统的原理,就出引发问题的真凶。
本周回顾了前几周学习到的常见性能优化方法。值得注意的是一定切记要避免过早优化,性能优化往往会提高复杂度,一方面降低了可维护性,另一方面也为适应复杂多变的新需求带来障碍。所以要逐步完善,首先保证能满足当前的性能要求。发现性能不满足要求或者出现性能瓶颈后,再根据性能分析的结果选择最重要的性能问题进行优化。
不能把性能工具当成性能分析和优化的全部,一方面性能分析和优化的核心是对系统和应用程序运行原理的掌握,性能工具只是辅助我们更快完成此过程的帮手;另一方面完善监控系统可以提供绝大部分性能分析所需的基准数据,从这些数据中很可能大致定位出性能瓶颈,也就不用再去手动执行各类工具了。
捞评论
- 除了USE原则,还有RED原则。更偏重于应用,在很多微服务中会用到。
- Rate: 每秒请求数量
- Errors: 失败的请求次数
- Duration: 处理一条请求所需的时间
- 想要学习eBPF来说,可以从BPF Compiler Collection(BCC)这个项目开始。BCC提供了很多短小的示例,可以快速了解eBPF的工作原理并熟悉eBPF程序的开发思路。了解这些基本的用法后,再去深入了解eBPF。
Lesson 53 套路篇:系统监控的综合思路
一个好的监控系统,不仅可以实时暴露系统的各种问题,更可以根据这些监控到的状态,自动分析和定位大致的瓶颈来源,从而更精确地把问题汇报给相关团队。
- 从系统来说,监控系统要涵盖系统的整体资源使用情况。如CPU、内存、磁盘、文件系统和网络等
- 从应用程序来说,监控系统要涵盖应用程序内部的运行状态。即包括进程的CPU、磁盘I/O等整体运行状况,也包括接口调用耗时、执行中的错误、内部对象的内存使用等程序内部的运行状况
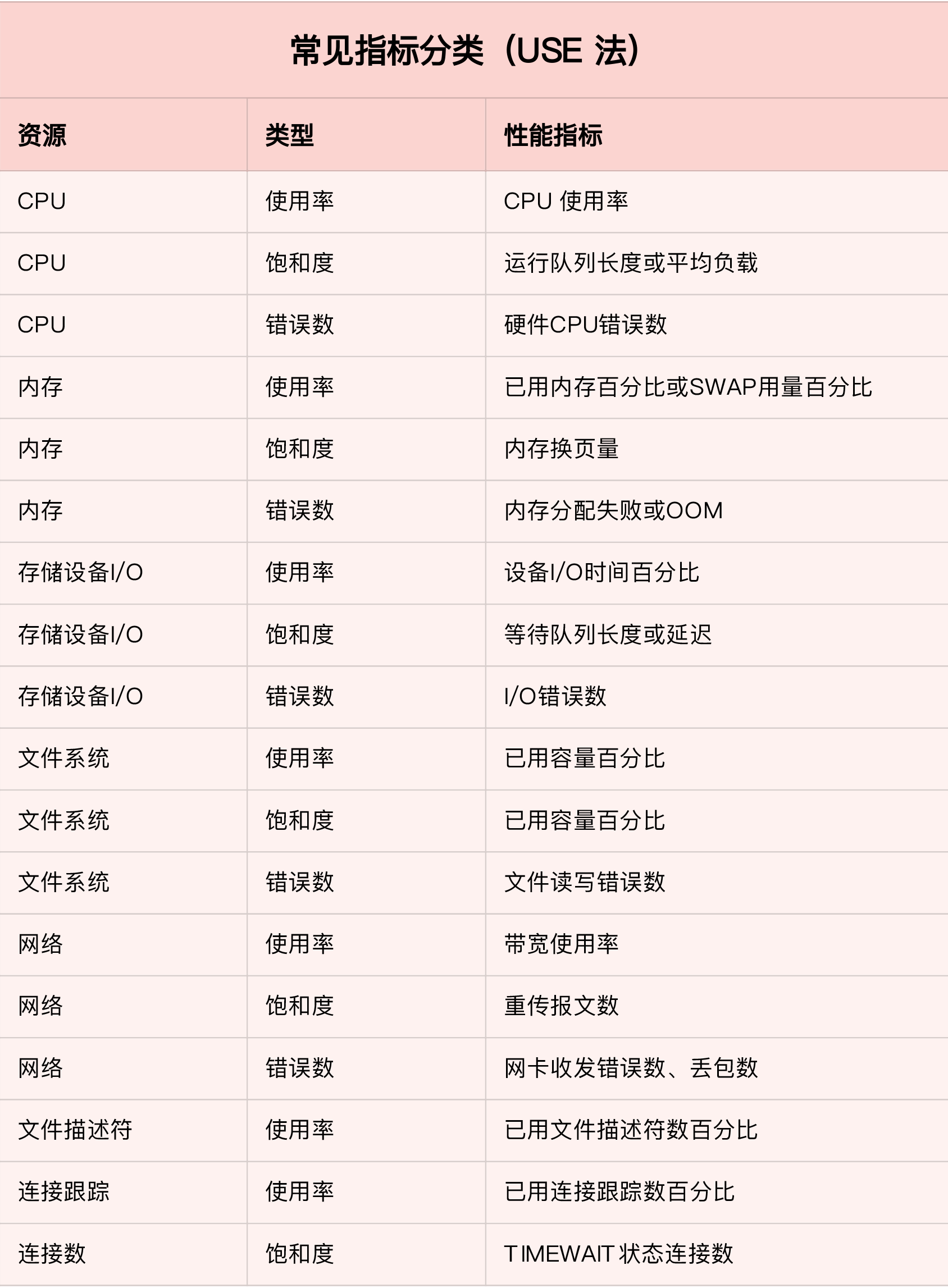
USE法
USE, Utilization Saturation and Errors
- 使用率,资源用于服务的时间或容量百分比
- 饱和度,资源的繁忙程度,通常和队列长度相关
- 错误数,表示发生错误的事件个数
常见指标分类如下图所示:
监控系统
一个完整的监控系统通常由数据采集、数据存储、数据查询和处理、告警以及可视化展示等多个模块组成。
常见的开源监控工具有Zabbix、Nagios、Prometheus等,下面介绍Prometheus的基本架构:
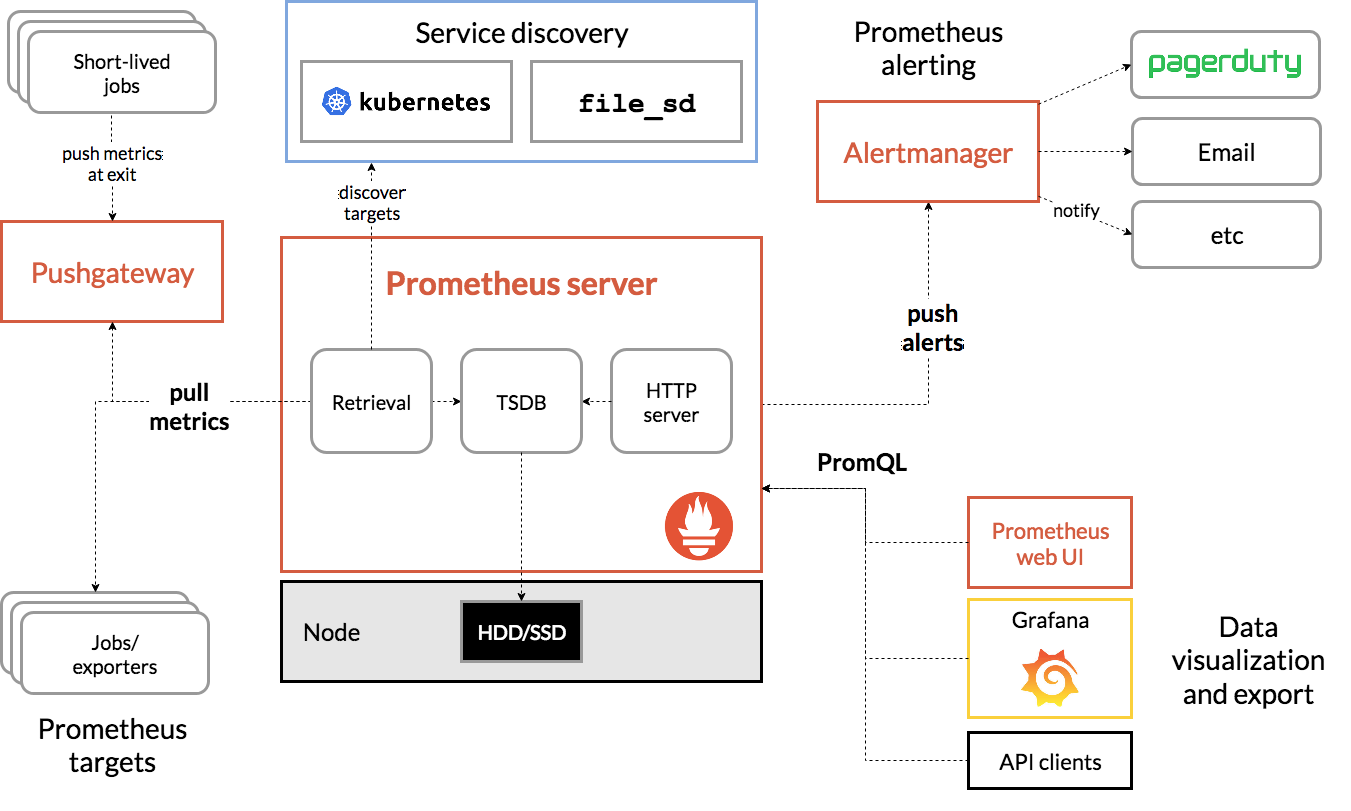
数据采集
Prometheus targets就是数据采集的对象,Retrieval负责采集这些数据。Prometheus支持两种采集模式:
- Pull模式,服务端的采集模块触发采集。只要采集目标提供HTTP接口即可(常用的采集模式)
- Push模式,各个采集目标主动向Push Gateway推送目标,再由服务器端从Gateway中拉取(移动应用中常用)
Prometheus提供服务发现机制,自动根据配置的规则动态发现需要监控的对象。在K8S容器平台中非常有效。
数据存储
TSDB(Time Series Database),负责将采集到的数据持久化到SSD等磁盘设备中。 TSDB是专门为时序数据设计的数据库,以时间为索引、数据量大且以追加的方式写入。
数据查询和处理
TSDB在存储数据的同时,还提供了数据查询和基本的数据处理功能。即PromQL语言,提供了简介的查询、过滤功能。
告警模块
AlertManager提供了告警功能,基于PromQL语言的触发条件、告警规则的配置管理以及告警的发送。还支持通过分组、抑制或者静默等多种方式来聚合同类告警。
可视化
Prometheus WebUI提供了简单的可视化界面。通常配合Grafana来构建强大的图形界面。
Lesson 54 套路篇:应用监控的一般思路
指标监控
应用程序的核心指标,不再是资源的使用情况,而是请求数、错误率和响应时间。
除了上述三个指标外,下面几种指标也是应用程序监控必不可少的,可以帮助我们快速定位性能瓶颈。
- 应用进程的资源使用情况,比如进程占用的CPU、内存、磁盘I/O、网络等。
- 应用程序之间的调用情况,如调用频率、错误数、延时等
- 可以迅速分析出一个请求处理的调用链中哪个组件导致性能问题
- 应用程序内部核心逻辑的运行情况,比如关键环节的耗时以及执行过程中的错误等
- 直接进入应用程序内部,定位到底是哪个处理环节的函数导致性能问题
由于业务系统通常会涉及到一连串的多个服务,形成一个复杂的分布式调用链。为了迅速定位这类跨应用的性能瓶颈,可以使用Zipkin、Jaeger、Pinpoint等各类开源工具来构建全链路跟踪系统。
日志监控
- 指标是特定时间段的数值型测量数据,通常以时间序列的方式处理,适合于实时监控
- 日志都是某个时间点的字符串消息,通常需要对搜索引擎进行索引后,才能进行查询和汇总分析
日志监控经典的方法是ELK技术栈,Elasticsearch、Logstash、Kibana三个组件的组合。
- Logstash负责从各个日志源采集日志,进行预处理,最后再把初步处理过的日志发送给Elasticsearch进行索引
- Elasticsearch负责对日志进行检索,并提供一个完整的全文搜索引擎
- Kibana负责对日志进行可视化分析,包括日志搜索、处理以及绚丽的仪表板展示
ELK中logstash资源消耗较大,在资源紧张时往往使用Fluentd来替代,即EFK技术栈。采集端还可以使用filebeat,架构拓展为filebeat-kafka(zookeeper)-logstash或sparkstreaming-es,除了日志查询外可以做业务关联等。
Lesson 55 套路篇:分析性能问题的一般步骤
在收到监控系统的告警,发现系统戏院或者应用程序出现性能瓶颈,如何进一步分析根源?
系统资源瓶颈
系统资源的瓶颈通过USE法,即使用率、饱和度和错误数三类指标来衡量。系统的资源可以分为硬件资源和软件资源两大类:
- CPU、内存、磁盘和文件系统以及网络等,都是常见的硬件资源
- 文件描述符、连接跟踪数、套接字缓冲区大小等都是典型的软件资源。
在收到监控系统告警后就可以对照这些资源列表,再根据指标的不同来定位。
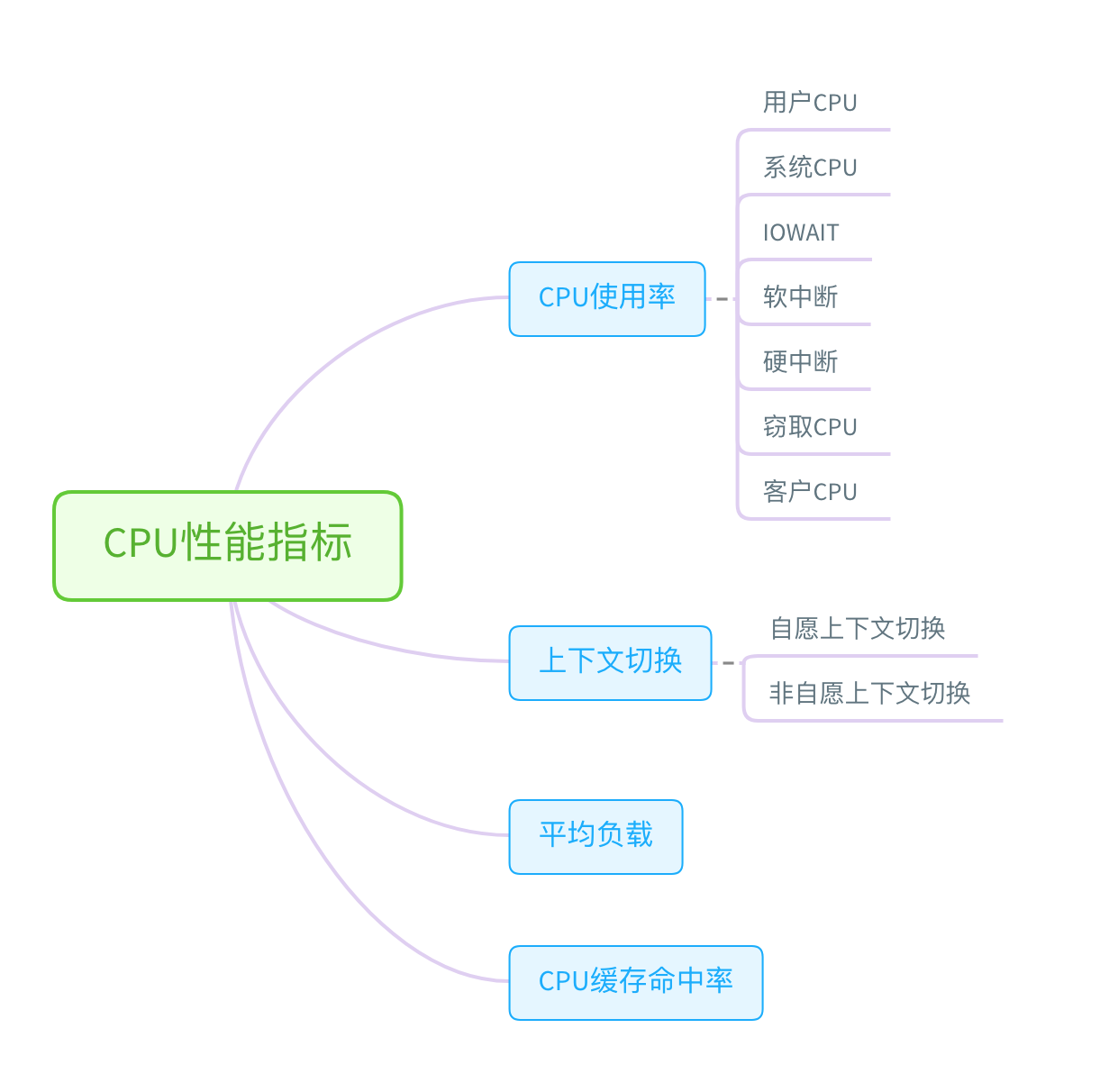
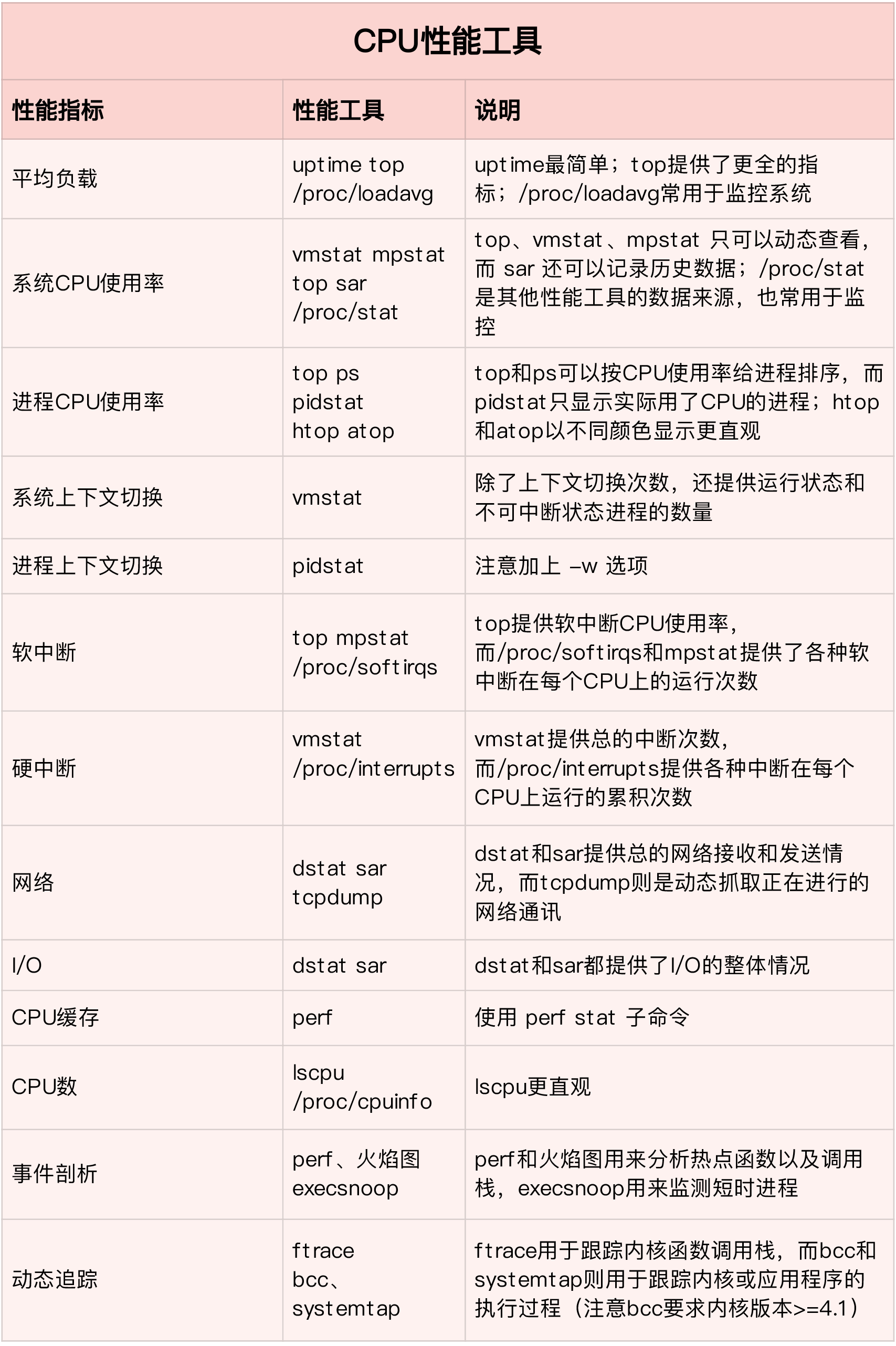
CPU性能分析
利用top、vmstat、pidstat、strace以及perf等几个常见的工具,获得CPU性能指标后,再结合进程与CPU的工作原理,就可以迅速定位CPU性能瓶颈的来源。
top、vmstat、pidstat等工具所汇报的CPU性能指标都来源于/proc文件系统,这些指标都应该通过监控系统监控起来。
比如当收到CPU使用率告警时,从监控系统中直接查询导致CPU使用率过高的进程,然后登陆到服务器分析该进程行为。可以使用strace查看进程的系统调用汇总,也可以使用perf找出热点函数,甚至可以使用动态追踪的方法来观察进程的当前执行过程,直到确定瓶颈个根源。
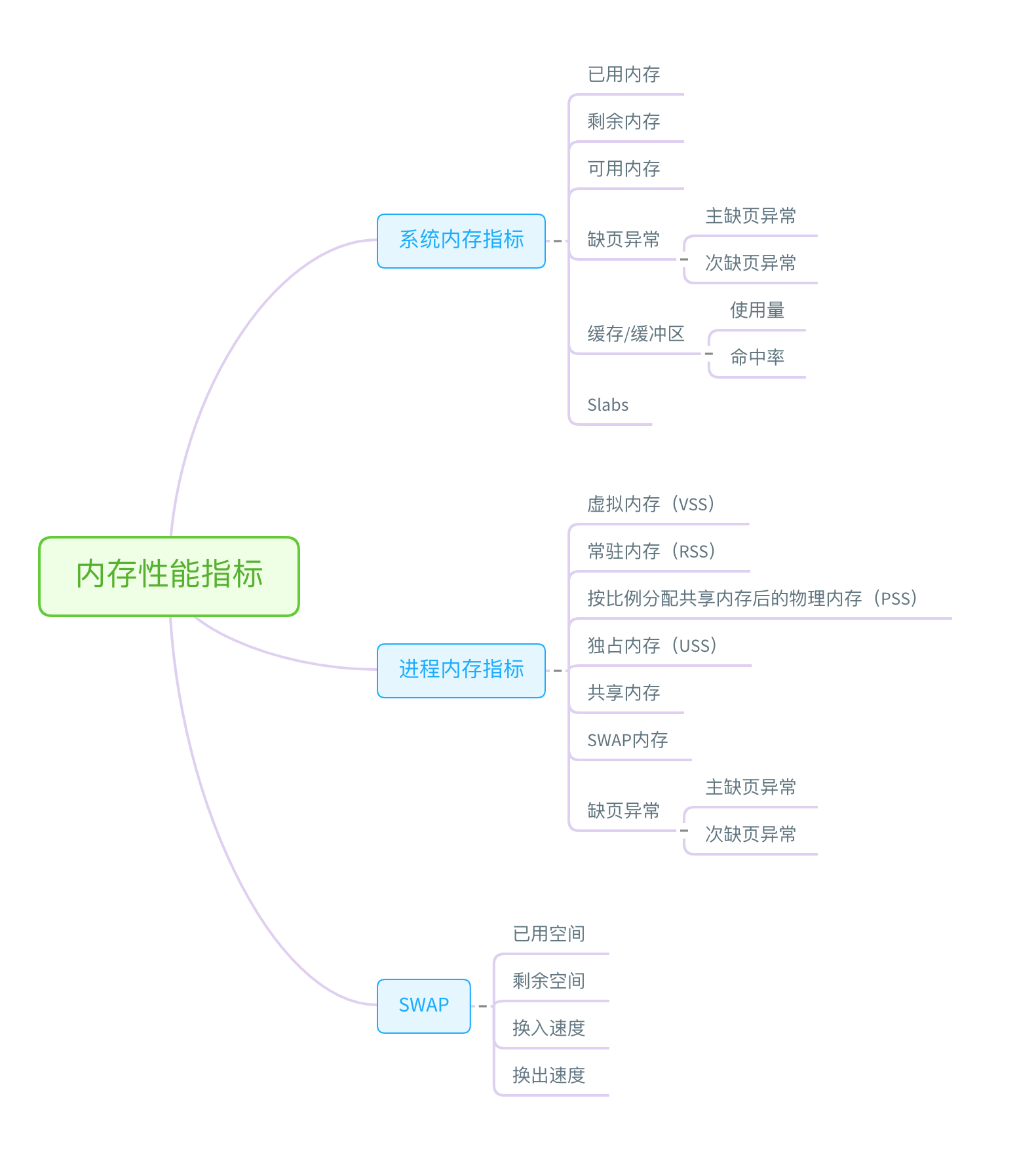
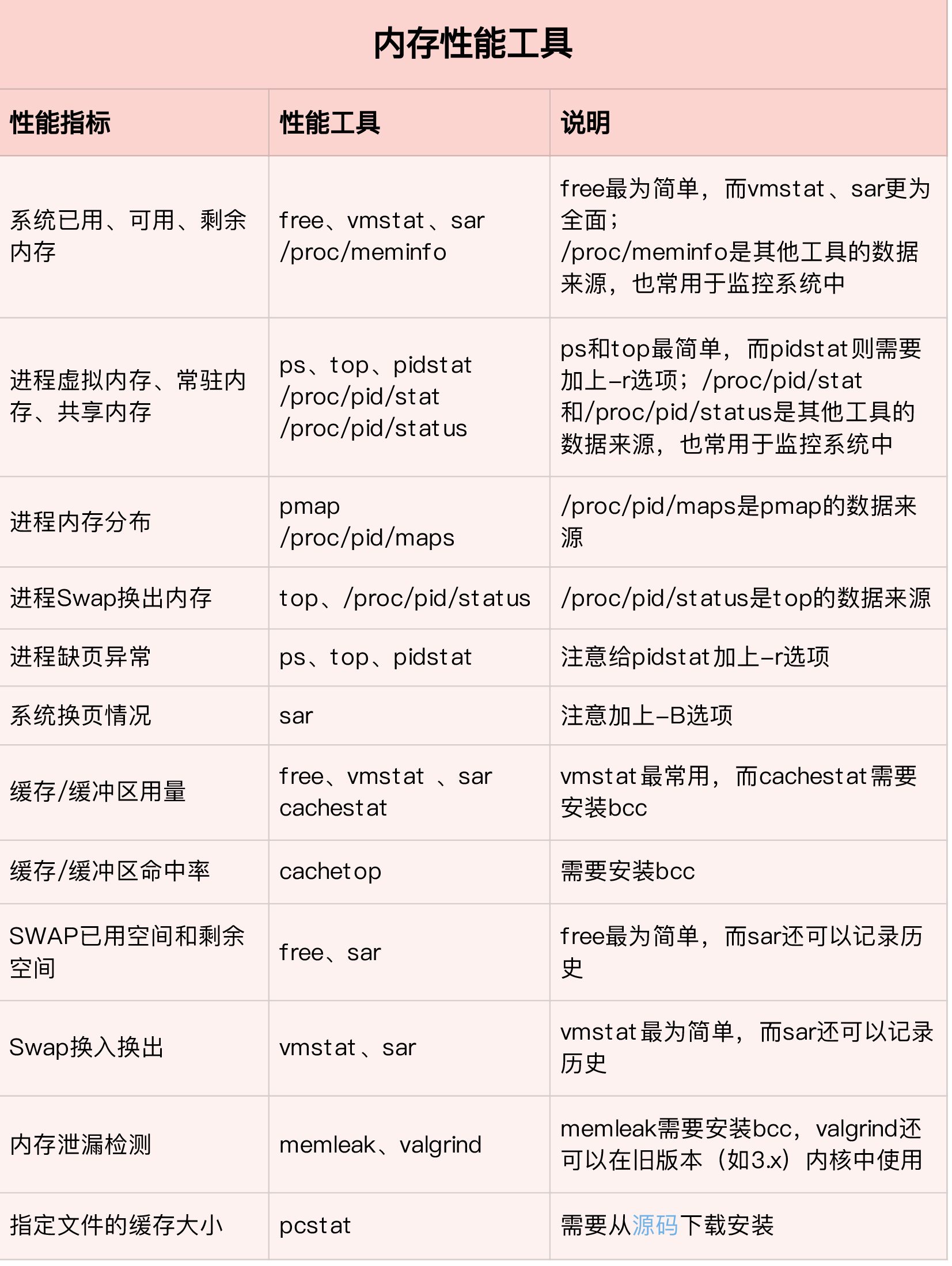
内存性能分析
通过free和vmstat输出的性能指标确认内存瓶颈,然后根据内存问题的类型,进一步分析内存的使用、分配、泄漏以及缓存等,最后找出问题的根源。
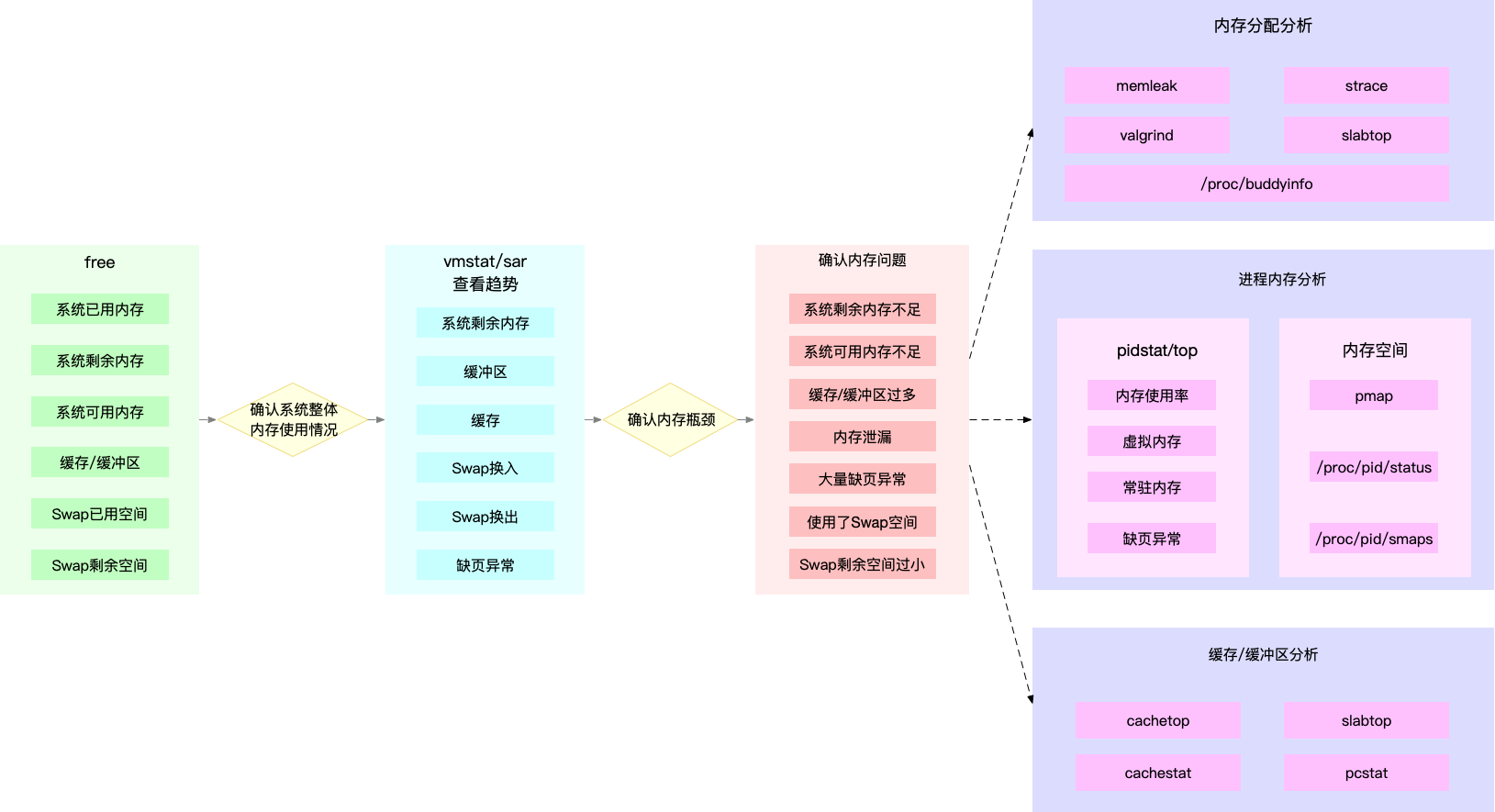
内存的性能指标也来源于/proc文件系统,它们也都应该通过监控系统监控起来。如当收到内存不足的告警时,可以从监控系统中找出占用内存最多的几个进程。然后根据这些进程的内存占用历史,观察是否存在内存泄漏问题。确定可疑进程后,再登陆服务器分析该进程的内存空间或内存分配,查明原因。
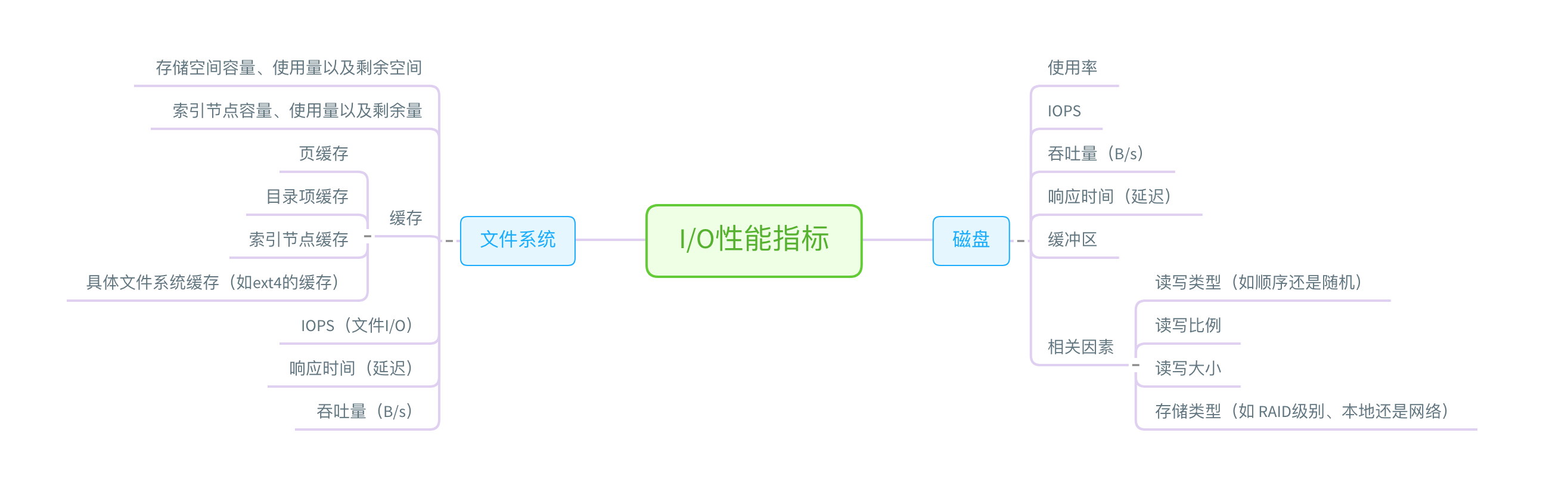
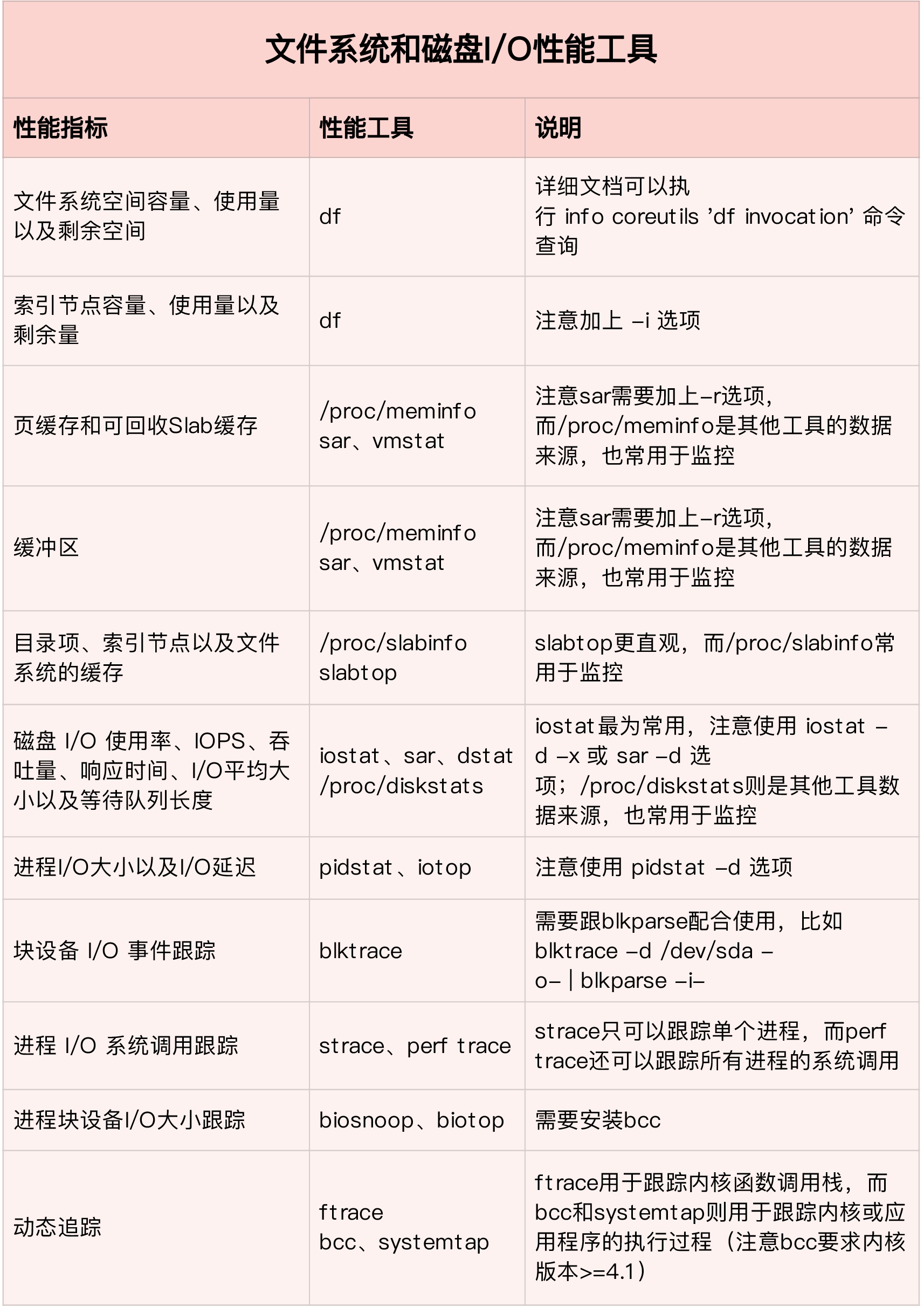
磁盘和文件系统I/O性能分析
当使用iostat发现磁盘I/O存在性能瓶颈后,可以再通过pidstat、vmstat等确认I/O的来源。再根据来源的不同进一步分析文件系统和磁盘的使用率、缓存以及进程的I/O等,从而找出I/O问题所在。
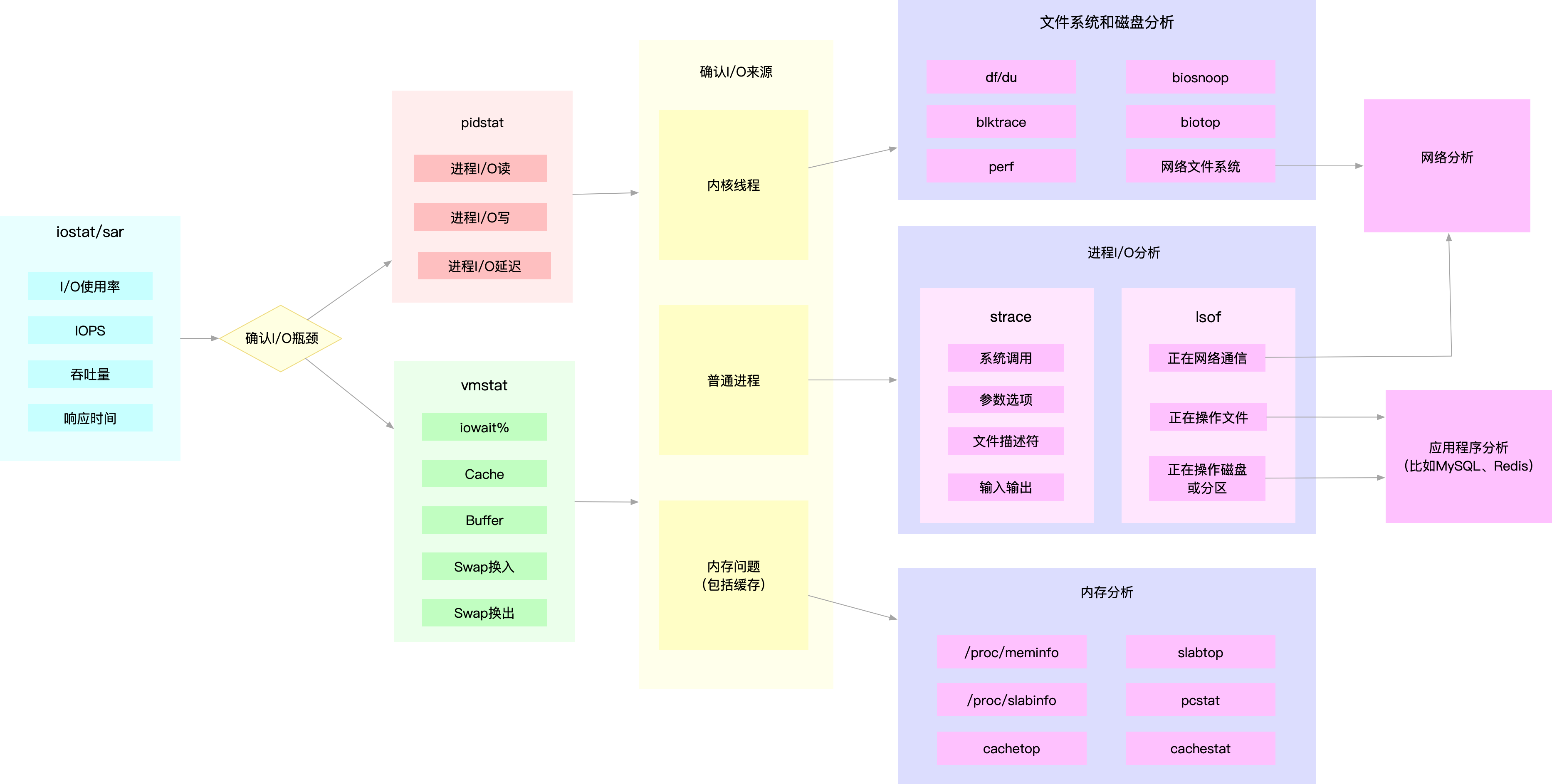
磁盘和文件系统的性能指标也来源于/proc和/sys文件系统,也应该通过监控系统监控起来。
如果发现某块磁盘的I/O使用率为100%时,首先可以从监控系统中,找出I/O最多的进程。然后登陆服务器借助strace、lsof、perf等工具,分析该进程的I/O行为。最后再结合应用程序的原理找出大量I/O的原因。
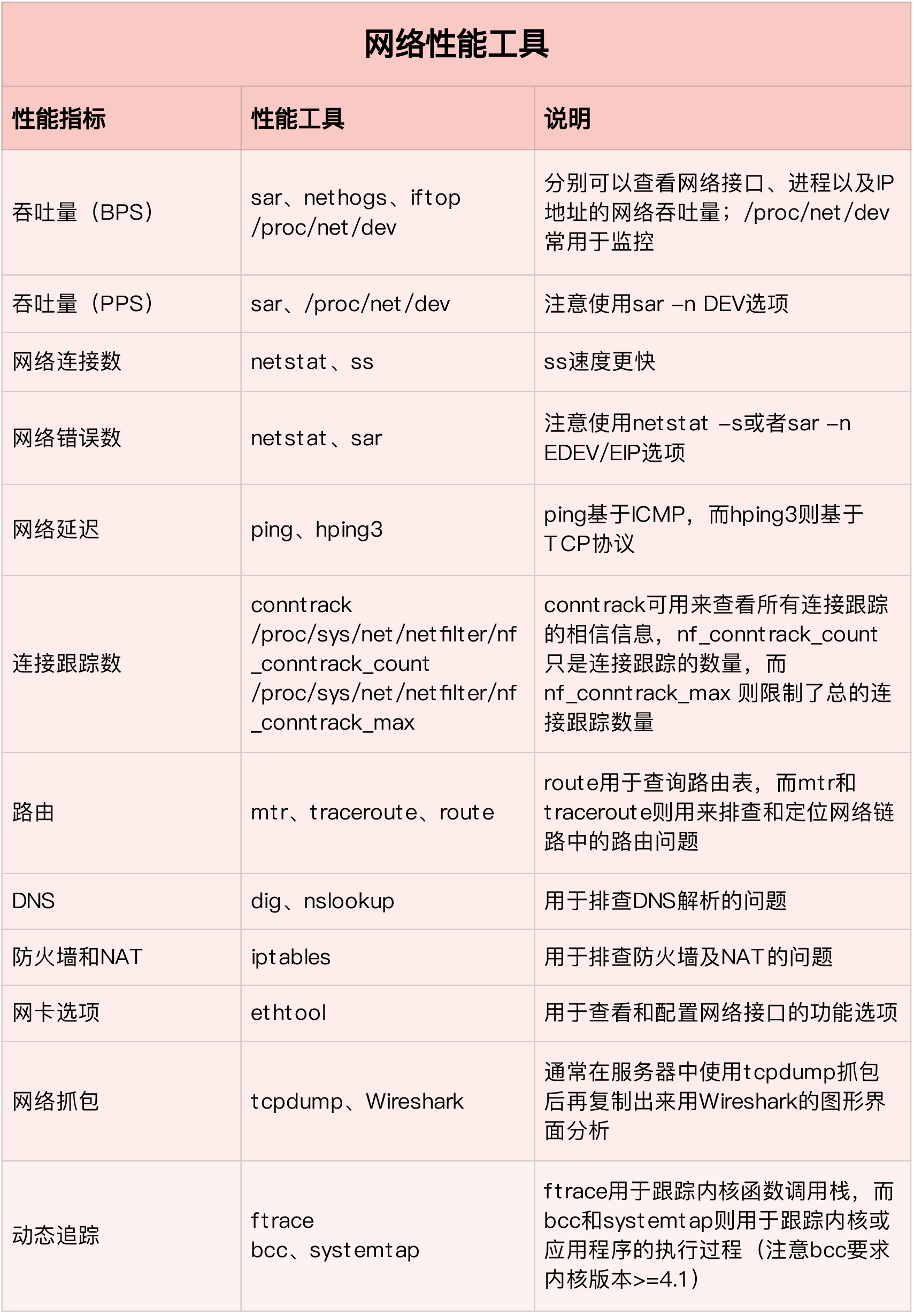
网络性能分析
网络性能其实包含两类资源,网络接口和内核资源。网络分析要从Linux网络协议栈的原理来切入。
- 链路层,从网络接口的吞吐量、丢包、错误以及软中断和网络功能卸载等角度分析;
- 网络层,从路由、分片、叠加网络等角度分析
- 传输层,从TCP、UDP的协议原理出发,从连接数、吞吐量、延迟重传等角度分析
- 应用层,从应用层协议、请求数、套接字缓存等角度进行分析
网络的性能指标也都来源于内核,包括/proc文件系统、网络接口以及conntrack等内核模块,这些指标同样需要被监控系统监控。
例如,当收到网络不同的告警时,就可以从监控系统中查找各个协议层的丢包指标,确认丢包所在的协议层。然后从监控系统的数据中,确认网络带宽、缓冲区、连接跟踪数等软硬件,是否存在性能瓶颈。最后再登录到服务器中,借助netstat、tcpdump、bcc等工具分析网络的收发数据,并且结合内核中的网络选项以及TCP等网络协议的原理找出问题所在。
应用程序瓶颈
应用程序瓶颈本质来源有三种:资源瓶颈、依赖服务瓶颈、应用自身瓶颈。
资源瓶颈可以用前面的方法来分析。
依赖服务的瓶颈,也就是诸如数据库、分布式缓存、中间件等应用程序,直接或间接调用的服务出现了性能问题从而导致应用程序的响应变慢或者错误率升高。使用全链路跟踪系统可以帮助快速定位这类问题的根源。
应用程序自身的性能问题,包括了多线程处理不当、死锁、业务的复杂度过高等,这类问题可以通过应用程序指标监控以及日志监控中,观察关键环节的耗时和内部执行过程中的错误,帮助缩小问题范围。
不过应用程序内部的状态,外部通常不能直接获取详细的性能数据,需要应用程序在设计和开发时提供这些指标。
如果上述手段还是无法找出瓶颈,可以通过系统资源模块提供的各类进程分析工具来定位分析。 比如:
- strace观察系统调用
- perf和火焰图分析热点函数
- 动态追踪技术分析进程的执行状态
Lesson 56 套路篇:优化性能问题的一般方法
系统优化
CPU优化
CPU性能优化的核心,在于排除所有不必要的工作、充分利用CPU缓存并减少进程程度对性能的影响。
- 把进程绑定到一个或者多个CPU上,充分利用CPU缓存的本地性,并减少进程间的相互影响。
- 为中断处理程序开启多CPU负载均衡,以便在发生大量中断时可以充分利用多CPU的优势分摊负载
- 使用cgroups等方法为进程设置资源限制,避免个别进程消耗过多的CPU。同时为核心应用程序设置更高的优先级,减少低优先级任务的影响
内存优化
- 除非有必要,Swap应该禁止掉。避免Swap的额外I/O,带来内存访问变慢的问题
- 使用Cgroups方法为进程设置内存限制。对于核心应用还应该降低oom_score,避免被OOM杀死
- 使用大页、内存池等方法,减少内存的动态分配,从而减少缺页异常
磁盘和文件系统I/O优化
- 通过SSD替代HDD、或者用RAID方法来提升I/O性能。
- 针对磁盘和应用程序I/O模式的特征,选择最合适的I/O调度算法。比如,SSD和虚拟机中的磁盘,通常用的是noop调度算法;数据库应用更推荐使用deadline算法
- 优化文件系统和磁盘的缓存、缓冲区,比如优化藏也的刷新频率、脏页限额,以及内核回收目录项缓存和索引节点缓存的倾向等
网络优化
从内核资源和网络协议的角度:
- 增大套接字缓冲区、连接跟踪表、最大半连接数、最大文件描述符数、本地端口范围等内核资源配额
- 减少TIMEOUT超时时间、SYN+ACK重传数、Keepalive探测时间等异常参数处理
- 还可以开启端口复用、反向地址校验,并调整MTU大小等降低内核的负担
从网络接口的角度:
- 将原来CPU上执行的工作,卸载到网卡中执行,即开启网卡的GRO、GSO、RSS、VXLAN等卸载功能;
- 也可以开启网络接口的多队列功能,这样每个队列就可以用不用的中断号,调度到不同CPU上执行
- 增大网络接口的缓冲区大小以及队列长度等,提升网络传输的吞吐量
在极限性能情况下,内核的网络协议栈可能是最主要的性能瓶颈,所以一般考虑绕过内核协议栈。
- DPDK技术跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时再结合大页、CPU绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率
- 内核自带的XDP技术,在网络包进入内核协议栈前,就对其进行处理。
应用程序优化
性能优化的最佳位置,还是应用程序内部
- 从CPU的角度来说,简化代码、优化算法、异步处理以及编译器优化等
- 从数据访问的角度,使用缓存、写时复制、增加I/O尺寸等都是常用的减少磁盘I/O的方法
- 从内存管理的角度,使用大页、内存池等方法,可以预先分配内存,减少内存的动态分配,从而更好地内存访问性能
- 从网络的角度,使用I/O多路复用,长连接代替短连接、DNS缓存等,可以优化网络I/O并减少网络请求数,从而减少网络延时带来的性能问题
- 从进程的工作模型来说,异步处理、多线程或多进程可以充分利用每一个CPU的处理能力,从而提高应用程序的吞吐能力
还可以使用消息队列,CDN、负载均衡等各种方法来优化应用程序的架构,将原来单机要承担的任务调度到多台服务器中并行处理。
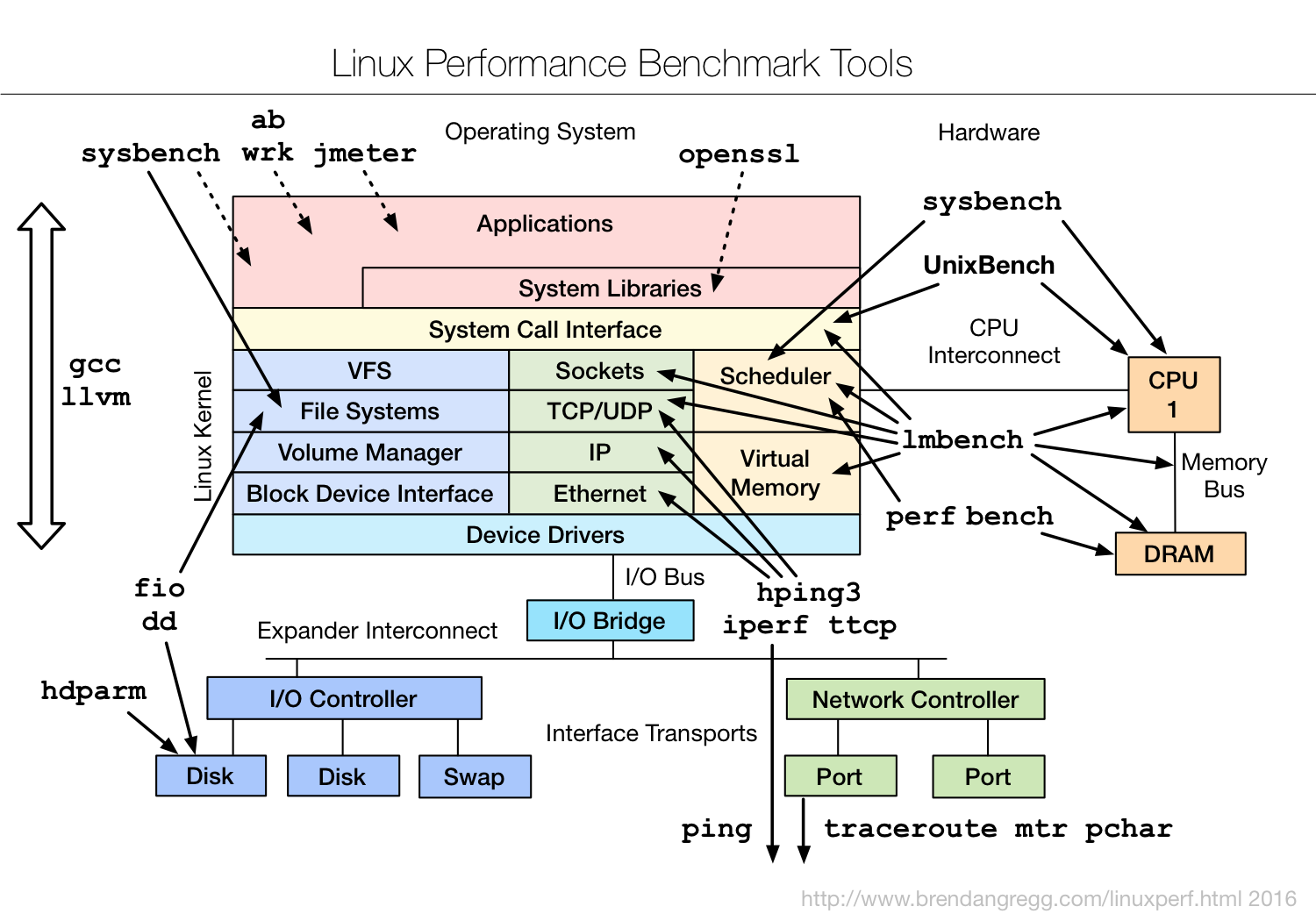
Lesson 57 套路篇:Linux性能工具速查
CPU性能工具
内存性能工具
磁盘I/O性能工具
网络性能工具

基准测试工具
- 在文件系统和磁盘I/O模块中,使用fio工具
- 在网络模块,使用iperf、pktgen等
- 在基于Nginx的案例中,使用ab、wrk等
现在重新回看Brendan Gregg的这张Linux基准测试工具图谱,收获良多。